پروفایلینگ یک تکنیک مفید برای شناسایی گلوگاههای عملکرد ، بررسی مصرف حافظه و به دست آوردن بینش درباره سربار جمعآوری زباله (Garbage Collection) و موارد دیگر است. اکوسیستم Go ابزارهای فوقالعادهای برای این منظور ارائه میدهد. امکان فعال و غیرفعال کردن پروفایلینگ به ویژه هنگام رفع اشکال در یک برنامه CLI نوشته شده با Go بسیار مفید است.
نقل و قول نویسنده:
شاید profiling برای حال حاضر قابل اهمیت نباشد اما روزی خواهد رسید که در بخش هایی از پروژه دچار مصرف بیش از حد memory, CPU خواهید شد و اینجاس که profiling به شما کمک خواهد کرد سریز منابع را پیدا کنید.
سعی کنید این مطلب را یاد بگیرید قطعا یک روزی با این موضوع مواجه خواهید شد.
چه زمانی پروفایل کنیم؟
موارد استفاده رایج پروفایلینگ عبارتند از:
- کشف گلوگاههای عملکرد و رفع آنها برای بهبود عملکرد کلی
- یافتن تخصیصهای اضافی حافظه و کاهش آنها به منظور کاهش تاثیر منفی Garbage Collection بر عملکرد.
- سرریز یا نشت حافظه یا CPU در بلند مدت (نشت منابع وقتی مشخص می شود که سرویس شما برای مدت طولانی چند روز در حال اجرا باشد.)
4.25.1 مدل ذهنی (mental) برای Go #
ممکن است بتوانید در نوشتن کد Go به مهارت بالایی برسید بدون اینکه درک دقیقی از نحوه عملکرد این زبان در پشت صحنه داشته باشید. اما وقتی به عملکرد و اشکالزدایی میرسیم، داشتن یک مدل ذهنی از جزئیات داخلی زبان به شدت به نفع شما خواهد بود. بنابراین، ابتدا یک مدل ابتدایی از Go را شرح میدهیم. این مدل به اندازه کافی خوب است که به شما کمک کند از اشتباهات رایج اجتناب کنید، اما تمامی مدلها محدودیت دارند، بنابراین توصیه میشود که برای حل مشکلات پیچیدهتر در آینده، به منابع تخصصیتر مراجعه کنید.
وظیفه اصلی Go، مشابه یک سیستمعامل، این است که منابع سختافزاری را چندوظیفهای و انتزاعی کند. این کار عمدتاً با استفاده از دو انتزاع اصلی انجام میشود:
- زمانبند Goroutine: مدیریت نحوه اجرای کد شما بر روی پردازندههای سیستم.
- جمعآوری زباله (Garbage Collector): حافظه مجازی را فراهم میکند که به طور خودکار در صورت نیاز آزاد میشود.
4.25.1.1 زمانبند (scheduler) گوروتین #
ابتدا با استفاده از مثال زیر در مورد زمانبند صحبت کنیم:
func main() {
res, err := http.Get("https://example.org/")
if err != nil {
panic(err)
}
fmt.Printf("%d\n", res.StatusCode)
}
در اینجا یک goroutine واحد داریم که آن را G1 مینامیم و این goroutine تابع main را اجرا میکند. تصویر زیر یک خط زمانی سادهشده از نحوه اجرای این goroutine روی یک پردازنده را نشان میدهد. ابتدا G1 بر روی پردازنده اجرا میشود تا درخواست HTTP را آماده کند. سپس پردازنده بیکار میشود زیرا goroutine باید منتظر شبکه بماند. در نهایت، goroutine دوباره روی پردازنده زمانبندی میشود تا کد وضعیت را چاپ کند.
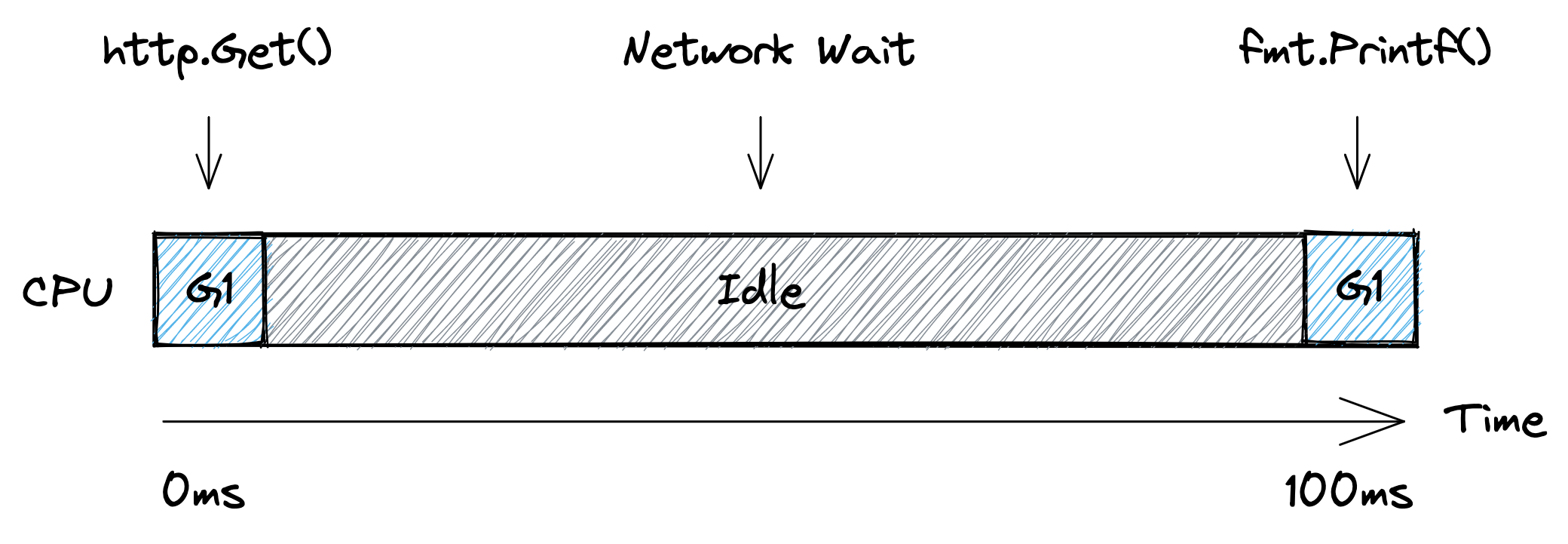
از دیدگاه زمانبند، برنامه بالا به این صورت اجرا میشود. ابتدا G1 در حال اجرا روی پردازنده 1 است. سپس goroutine از پردازنده خارج میشود و در حال انتظار برای شبکه قرار میگیرد. زمانی که زمانبند متوجه میشود شبکه پاسخ داده است (با استفاده از ورودی/خروجی غیرمسدودکننده، مشابه Node.js) گوروتین را به عنوان " آماده اجرا
" علامتگذاری میکند. و به محض اینکه یک هسته پردازنده آزاد شود، goroutine دوباره شروع به اجرا میکند. در مثال ما تمام هستهها در دسترس هستند، بنابراین G1 بلافاصله بدون صرف زمانی در حالت “آماده اجرا” میتواند به اجرای تابع fmt.Printf() بر روی یکی از پردازندهها برگردد.
در اکثر مواقع، برنامههای Go چندین goroutine را به طور همزمان اجرا میکنند، بنابراین تعدادی از goroutineها در حال اجرای روی برخی از هستههای پردازنده هستند، تعداد زیادی از goroutineها به دلایل مختلف در حالت “انتظار” قرار دارند، و ایدهآل این است که هیچ goroutineی در حالت “آماده اجرا” نباشد، مگر اینکه برنامه شما بار پردازشی بسیار بالایی بر روی پردازنده ایجاد کند. یک مثال از این حالت را میتوان در زیر مشاهده کرد.
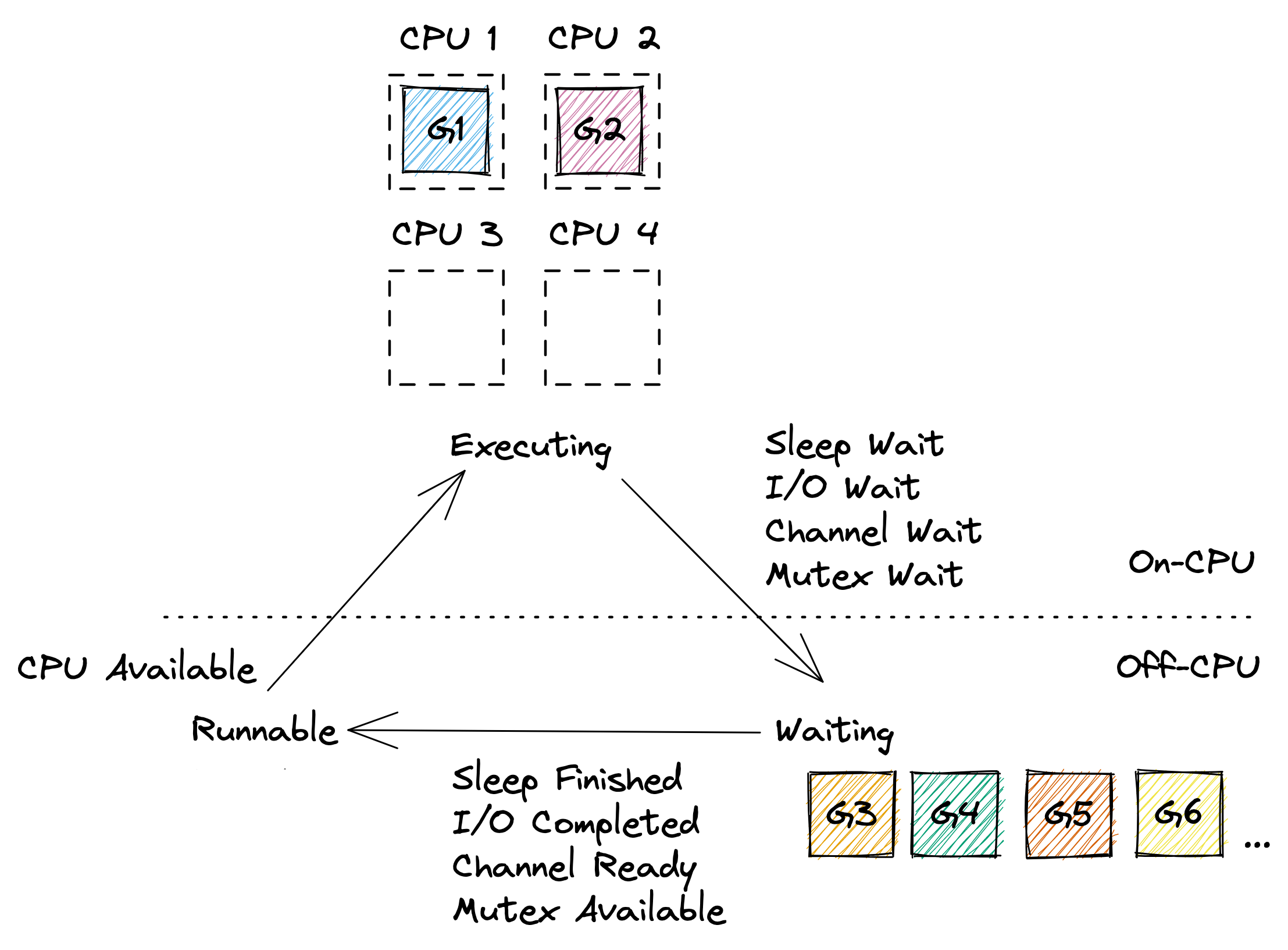
البته مدل بالا بسیاری از جزئیات را نادیده میگیرد. در واقعیت، زمانبند Go بر روی نخهایی (threads) که توسط سیستمعامل مدیریت میشوند، کار میکند و حتی خود پردازندهها نیز قادر به استفاده از هایپرتردینگ (hyper-threading) هستند که میتوان آن را نوعی زمانبندی در نظر گرفت.
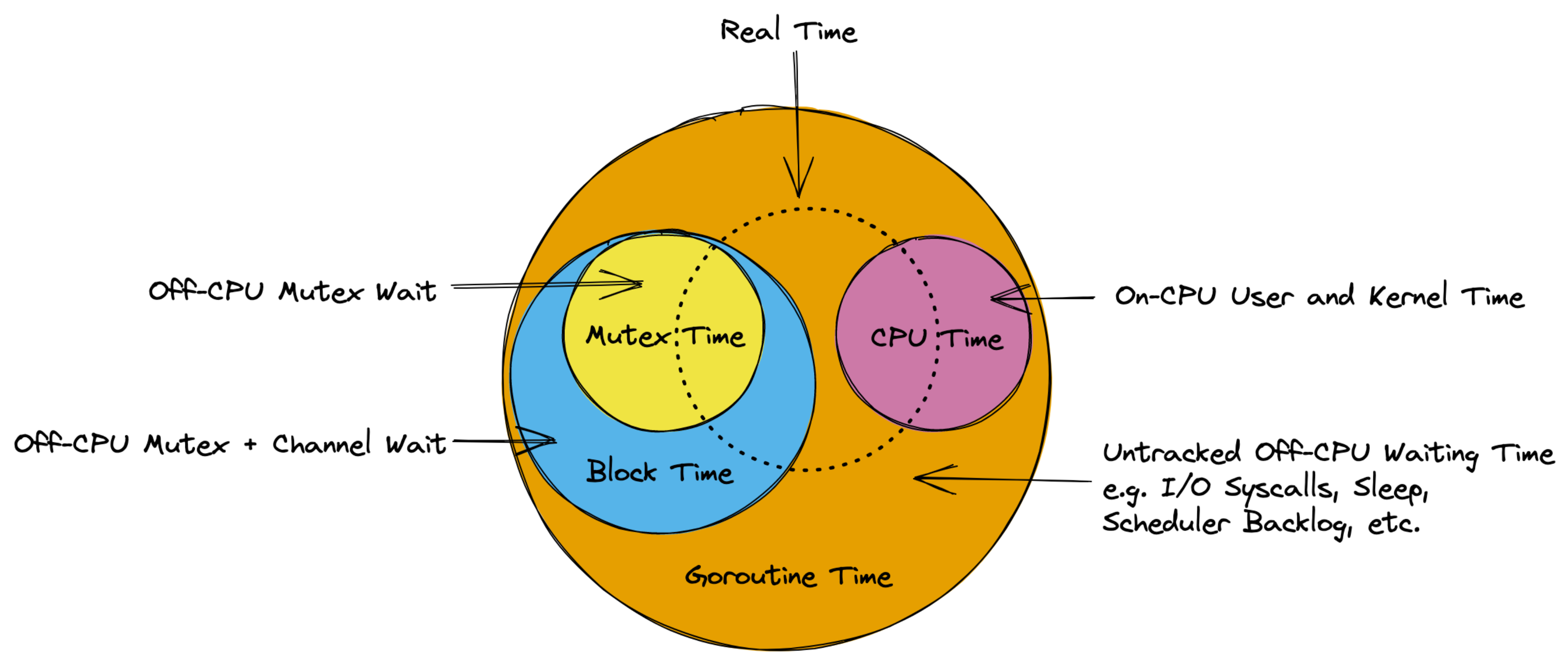
با این حال، مدل فوق باید برای درک بخشهای باقیمانده از این راهنما کافی باشد. به طور خاص، باید روشن شود که زمان اندازهگیریشده توسط پروفایلرهای مختلف Go در اصل زمانی است که goroutineهای شما در حالت “اجرا” (Executing) و “انتظار” (Waiting) صرف میکنند، همانطور که در نمودار زیر نشان داده شده است.
4.25.1.2 زباله جمع کن (Garbage Collector) #
دیگر انتزاع مهم در Go، جمعآوری زباله (Garbage Collector) است. در زبانهایی مانند C، برنامهنویس باید به صورت دستی تخصیص و آزادسازی حافظه را با استفاده از malloc() و free() مدیریت کند. این رویکرد کنترل خوبی ارائه میدهد، اما در عمل بسیار مستعد خطا است. یک جمعآوریکننده زباله (GC) میتواند این بار را کاهش دهد، اما مدیریت خودکار حافظه ممکن است به راحتی به یک گلوگاه عملکرد تبدیل شود. این بخش از راهنما یک مدل ساده برای GC در Go ارائه میدهد که برای شناسایی و بهینهسازی مشکلات مربوط به مدیریت حافظه مفید خواهد بود.
برای یک راهنمای جامعتر درباره GC در Go، به مستندات رسمی مراجعه کنید.
4.25.1.2.1 پشته (Stack) #
با اصول اولیه شروع کنیم. Go میتواند حافظه را در یکی از دو مکان تخصیص دهد: پشته یا هیپ. هر goroutine پشته خاص خود را دارد که یک ناحیه پیوسته از حافظه است. علاوه بر این، یک ناحیه بزرگ از حافظه وجود دارد که بین goroutineها به اشتراک گذاشته میشود و به آن هیپ میگویند. این حالت را میتوان در تصویر زیر مشاهده کرد.
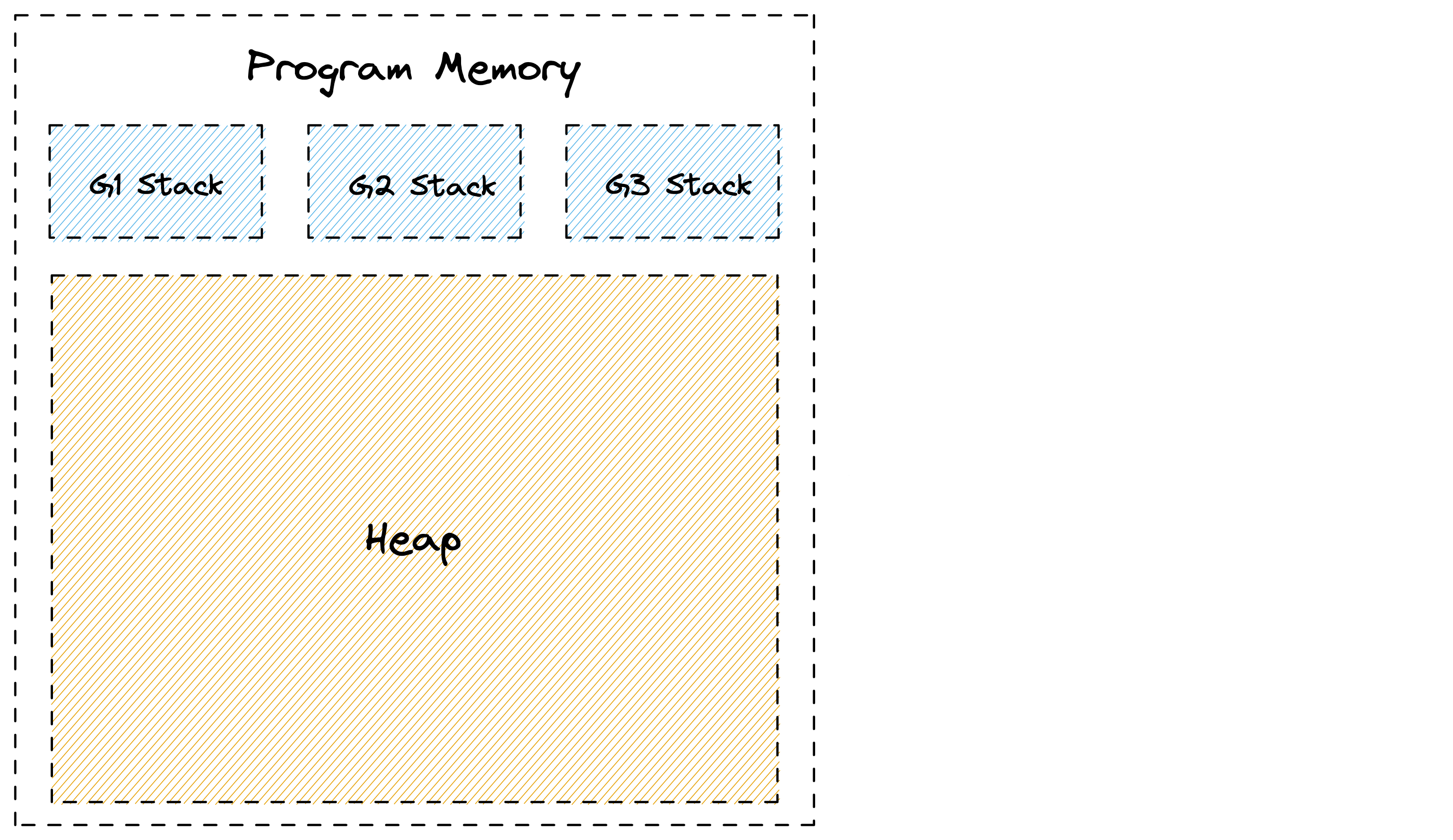
وقتی یک تابع تابع دیگری را فراخوانی میکند، یک بخش مخصوص روی پشته به آن اختصاص داده میشود که به آن «فریم پشته» (stack frame) میگویند و میتواند برای قرار دادن متغیرهای محلی از آن استفاده کند. یک اشارهگر پشته (stack pointer) برای شناسایی محل آزاد بعدی در فریم استفاده میشود. زمانی که یک تابع به پایان میرسد، دادههای فریم قبلی به سادگی با بازگرداندن اشارهگر پشته به انتهای فریم قبلی حذف میشوند. دادههای فریم همچنان میتوانند در پشته باقی بمانند و با فراخوانی بعدی تابع بازنویسی شوند. این فرآیند بسیار ساده و کارآمد است زیرا Go نیازی به پیگیری هر متغیر ندارد.
func main() {
sum := 0
sum = add(23, 42)
fmt.Println(sum)
}
func add(a, b int) int {
return a + b
}
برای درک بهتر این موضوع، به مثال زیر توجه کنید:
در اینجا یک تابع main() داریم که با رزرو مقداری فضا روی پشته برای متغیر sum شروع میشود. وقتی تابع add() فراخوانی میشود، یک فریم مخصوص برای نگه داشتن پارامترهای محلی a و b به آن اختصاص داده میشود. پس از اتمام اجرای add()، دادههای آن با بازگرداندن اشارهگر پشته به انتهای فریم تابع main() حذف میشوند و متغیر sum با نتیجه بهروز میشود. در همین حال، مقادیر قدیمی تابع add() فراتر از اشارهگر پشته باقی میمانند تا با فراخوانی بعدی تابع بازنویسی شوند. در زیر یک تصویرسازی از این فرآیند آمده است:
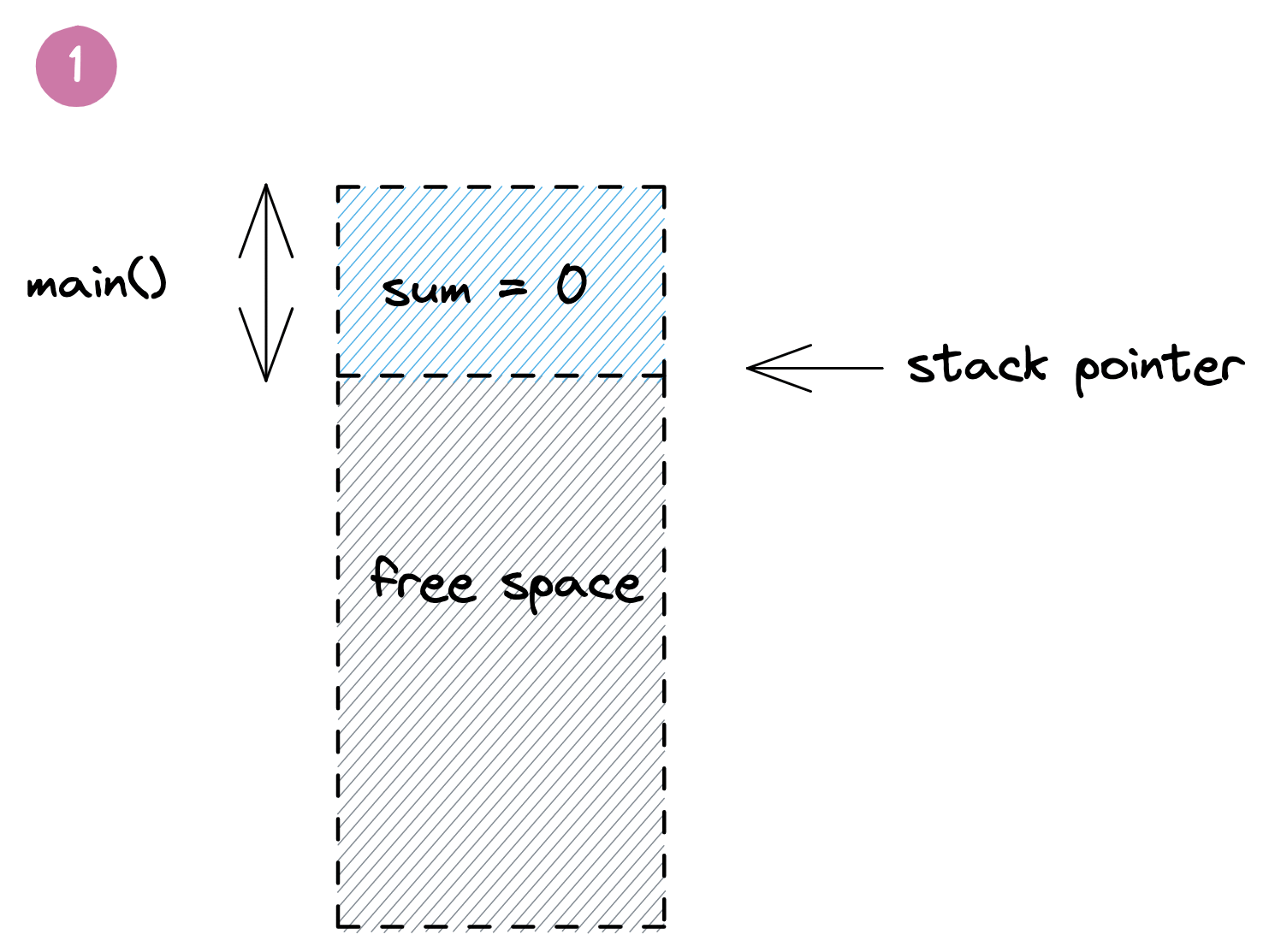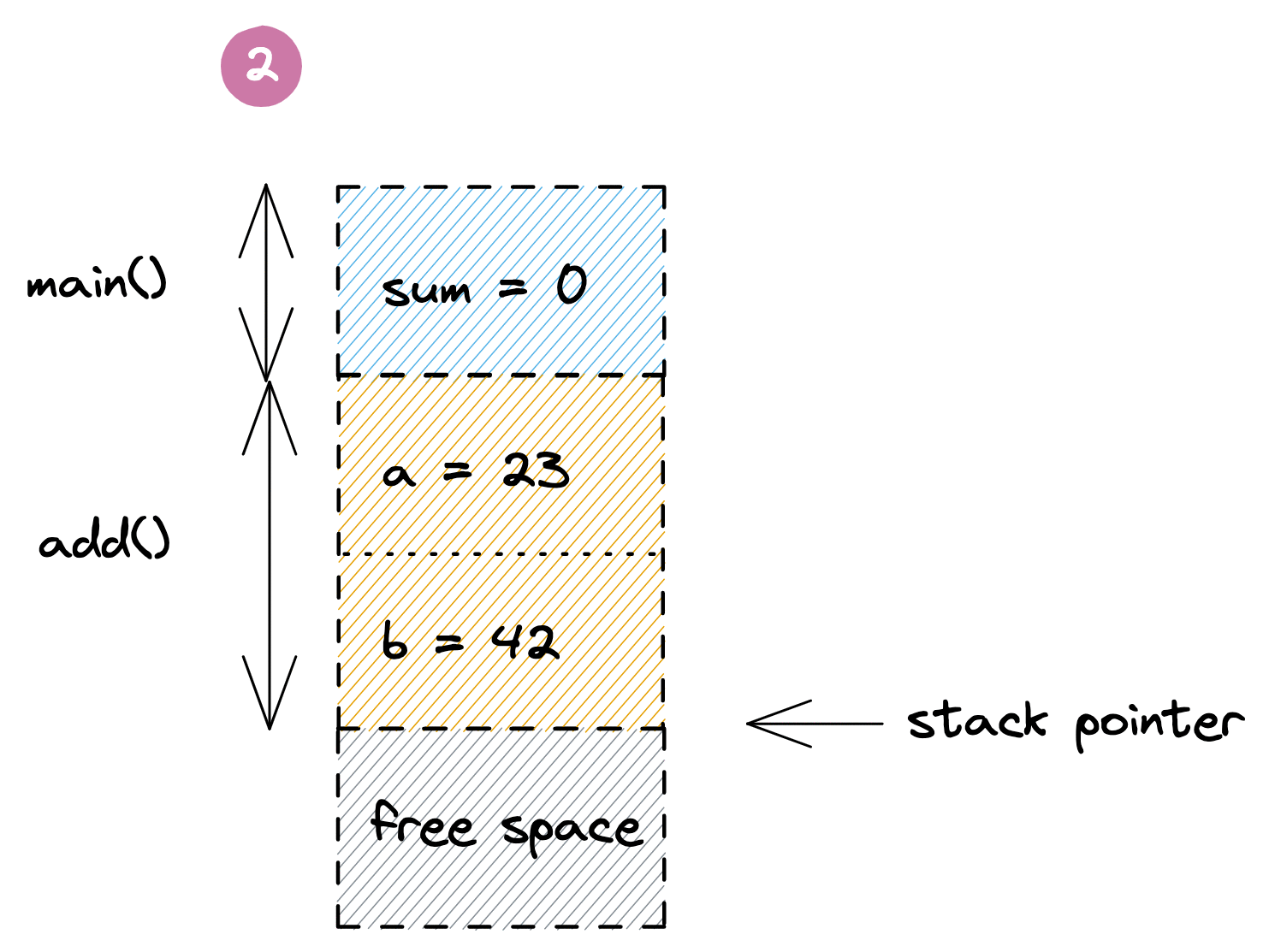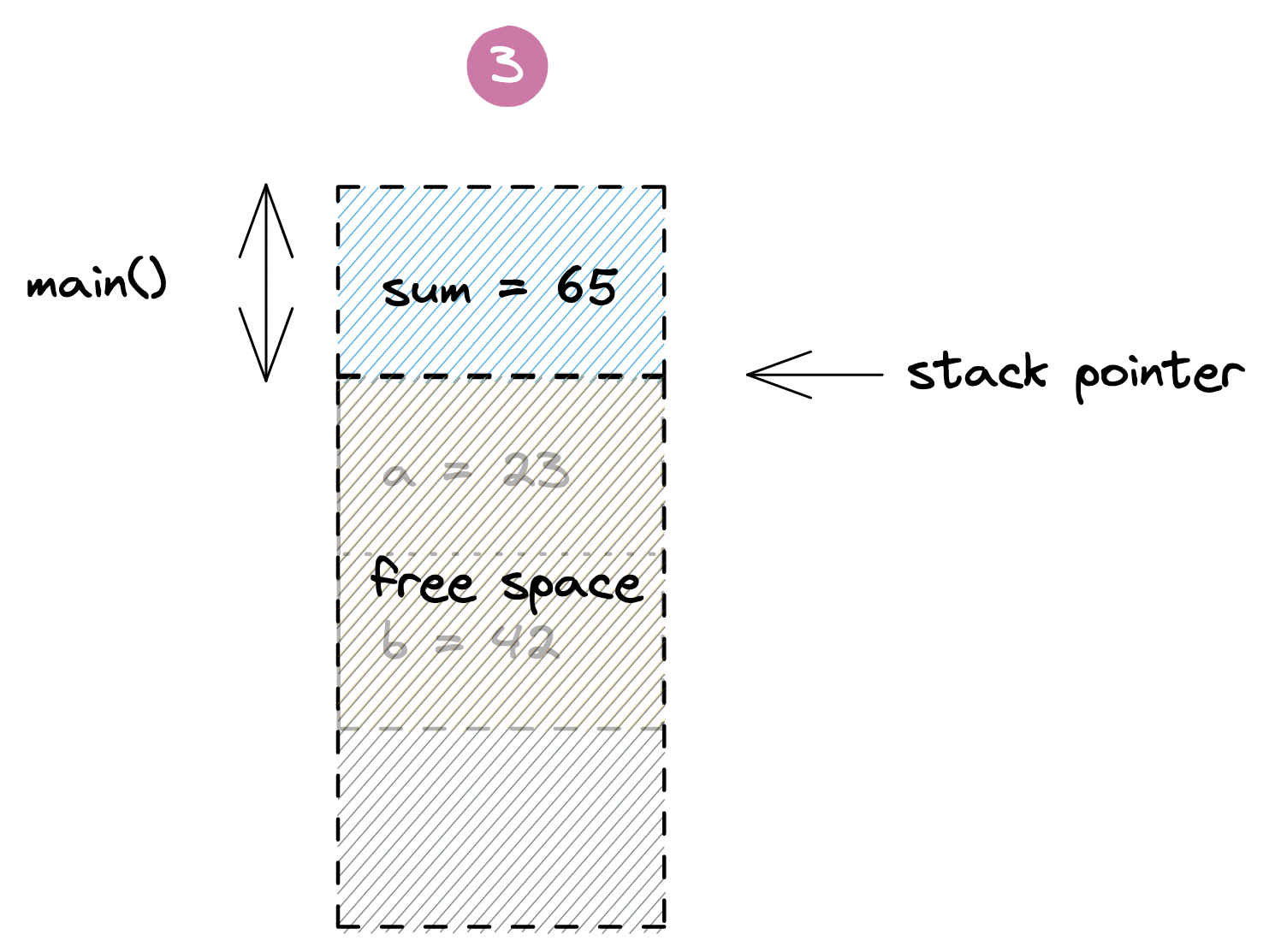
مثال بالا به شدت ساده شده است و بسیاری از جزئیات مانند مقادیر بازگشتی، اشارهگرهای فریم، آدرسهای بازگشت و درونخطیسازی (inlining) توابع را حذف کرده است. در واقع، از نسخه Go 1.17 به بعد، ممکن است برنامه بالا نیازی به فضای پشته نداشته باشد، زیرا مقدار کم داده میتواند توسط کامپایلر با استفاده از ثباتهای پردازنده (CPU registers) مدیریت شود. اما این مسئله مشکلی ایجاد نمیکند. این مدل همچنان به شما یک شهود معقول از نحوه تخصیص و حذف متغیرهای محلی در برنامههای پیچیدهتر Go روی پشته میدهد.
شاید در این مرحله این سوال برای شما پیش بیاید که چه اتفاقی میافتد اگر فضای پشته تمام شود. در زبانهایی مانند C، این موضوع باعث خطای سرریز پشته (stack overflow) میشود. اما در Go، این مشکل به صورت خودکار با ایجاد یک نسخه کپی از پشته که دو برابر بزرگتر است، مدیریت میشود. این قابلیت به goroutineها اجازه میدهد که با پشتههای بسیار کوچک، معمولاً 2 کیلوبایت، شروع کنند و یکی از عوامل اصلی مقیاسپذیری بیشتر goroutineها نسبت به نخهای سیستمعامل همین موضوع است.
4.25.1.2.2 هیپ (Heap) #
تخصیصهای پشته عالی هستند، اما در بسیاری از موارد Go نمیتواند از آنها استفاده کند. رایجترین حالت زمانی است که باید اشارهگری به یک متغیر محلی از یک تابع بازگردانده شود. این موضوع را میتوان در نسخه اصلاحشده مثال تابع add() که در بالا آمد، مشاهده کرد:
func main() {
fmt.Println(*add(23, 42))
}
func add(a, b int) *int {
sum := a + b
return &sum
}
در حالت عادی، Go میتواند متغیر sum را داخل تابع add() روی پشته تخصیص دهد. اما همانطور که یاد گرفتیم، این دادهها هنگام بازگشت تابع add() از بین میروند. بنابراین، برای بازگرداندن ایمن یک اشارهگر به &sum، Go باید حافظه را از خارج از پشته تخصیص دهد. اینجا است که هیپ وارد عمل میشود.
هیپ برای ذخیرهسازی دادههایی استفاده میشود که ممکن است پس از پایان اجرای تابع سازنده، همچنان مورد نیاز باشند، همچنین برای هر دادهای که بین goroutineها با استفاده از اشارهگرها به اشتراک گذاشته میشود. اما این سوال پیش میآید که چگونه این حافظه آزاد میشود؟ چون برخلاف تخصیصهای پشته، تخصیصهای هیپ را نمیتوان به محض اتمام تابعی که آنها را ایجاد کرده، حذف کرد.
Go این مشکل را با استفاده از جمعآوری زباله داخلی (GC) خود حل میکند. جزئیات پیادهسازی آن بسیار پیچیده است، اما از یک دید کلی، GC حافظه شما را به این شکل مدیریت میکند. در تصویر زیر میبینید که سه goroutine دارای اشارهگرهایی به تخصیصهای سبز رنگ روی هیپ هستند. برخی از این تخصیصها همچنین به تخصیصهای سبز دیگری اشاره میکنند. علاوه بر این، تخصیصهای خاکستری وجود دارند که ممکن است به تخصیصهای سبز یا یکدیگر اشاره کنند، اما خودشان توسط تخصیصهای سبز مرجع نشدهاند. این تخصیصها زمانی قابل دسترس بودند، اما اکنون به عنوان زباله در نظر گرفته میشوند. این اتفاق ممکن است زمانی رخ دهد که تابعی که اشارهگرهای آنها را روی پشته ایجاد کرده بود بازگردد، یا مقدارشان بازنویسی شده باشد. وظیفه GC این است که به صورت خودکار این تخصیصها را شناسایی و آزاد کند.
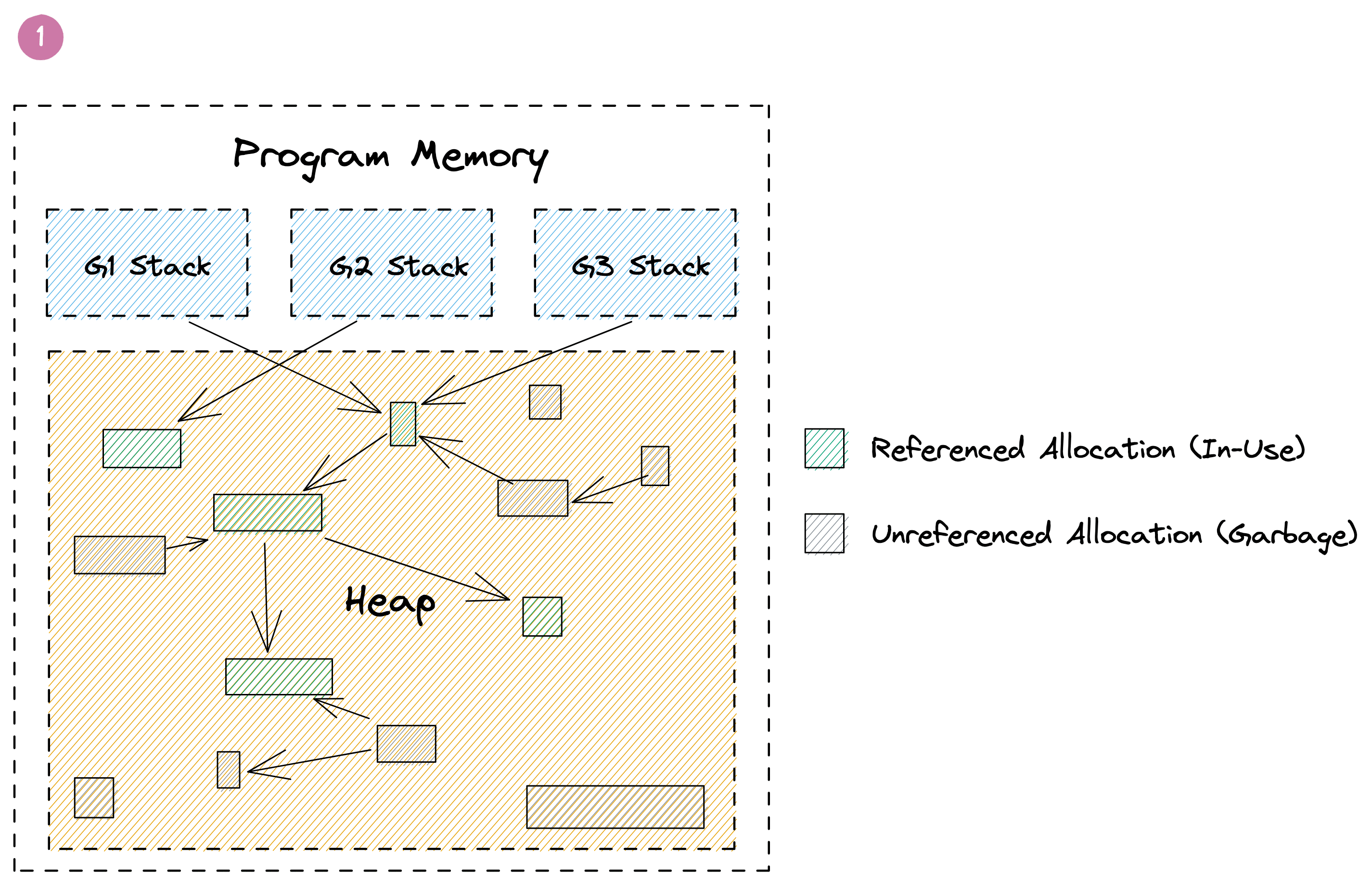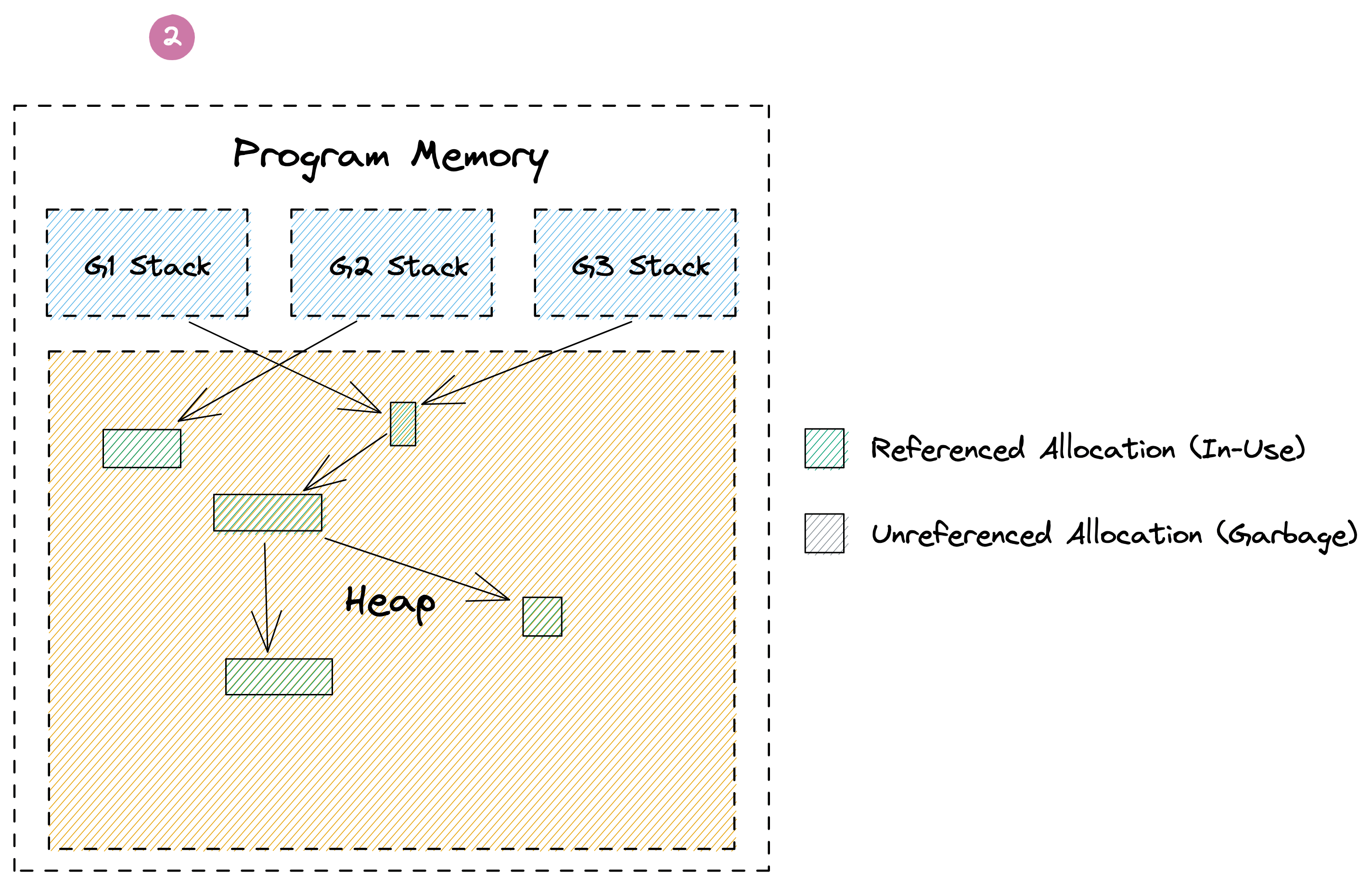
اجرای جمعآوری زباله (GC) شامل پیمایش گرافهای پرهزینه و تخلیه کش (cache thrashing) است. این فرایند حتی نیاز به فازهای متوقفکننده کل جهان (stop-the-world) دارد که اجرای کل برنامه شما را متوقف میکند. خوشبختانه نسخههای اخیر Go این زمان را به کسری از یک میلیثانیه کاهش دادهاند، اما بسیاری از هزینههای باقیمانده ذاتاً به هر GC مربوط میشود. در واقع، معمولاً ۲۰ تا ۳۰ درصد از اجرای یک برنامه Go صرف مدیریت حافظه میشود.
بهطور کلی، هزینه GC متناسب با مقدار تخصیصهای هیپ (heap allocations) است که برنامه شما انجام میدهد. بنابراین وقتی صحبت از بهینهسازی هزینههای مرتبط با حافظه میشود، شعار این است:
- کاهش (Reduce): سعی کنید تخصیصهای هیپ را به تخصیصهای پشته تبدیل کنید یا از آنها بهطور کلی اجتناب کنید. کاهش تعداد اشارهگرها در هیپ نیز کمک میکند.
- بازاستفاده (Reuse): تخصیصهای هیپ را دوباره استفاده کنید به جای اینکه آنها را با تخصیصهای جدید جایگزین کنید.
- بازیافت (Recycle): برخی از تخصیصهای هیپ غیرقابل اجتناب هستند. بگذارید GC آنها را بازیافت کند و بر روی مسائل دیگر تمرکز کنید.
همانند مدل ذهنی قبلی در این راهنما، همه موارد بالا نمایی به شدت ساده شده از واقعیت است. اما امیدوارم که این مدل به اندازه کافی مفید باشد تا باقیمانده این راهنما را درک کنید و شما را به مطالعه مقالات بیشتری در این زمینه ترغیب کند.
4.25.2 درک عمیق پروفایلرهای (Profilers) گو #
در اینجا مروری بر پروفایلرهای ساختهشده در زمان اجرای Go (Go runtime) ارائه میشود. برای جزئیات بیشتر، به لینکها مراجعه کنید.
در زیر جدول مربوط به پروفایلرهای مختلف موجود در Go ارائه شده است:
| ویژگی | CPU | Memory | Block | Mutex | Goroutine | ThreadCreate |
|---|---|---|---|---|---|---|
| Production Safety | ✅ | ✅ | ⚠ (1.) | ✅ | ⚠️ (2.) | 🐞 (3.) |
| نرخ ایمنی | default | default | ❌ (1.) | 100 | 1000 goroutines | - |
| دقت | ⭐️⭐️ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | - |
| عمق حداکثر پشته | 64 | 32 | 32 | 32 | 32 - 100 (4.) | - |
| برچسبهای پروفایلر | ✅ | ❌ | ❌ | ❌ | ✅ | - |
- پروفایلر بلوک (block profiler): اگر به درستی پیکربندی نشده باشد، پروفایلر بلوک میتواند منبع قابل توجهی از بار CPU باشد.
- توقفهای جهانی (stop-the-world): یک توقف جهانی
O(N)وجود دارد که N تعداد goroutineها است. انتظار میرود هر goroutine بین~1-10میکروثانیه توقف داشته باشد. - پروفایلر ThreadCreate: این پروفایلر به طور کامل معیوب است و بهتر است از آن استفاده نکنید.
- عمق حداکثر پشته: این مورد به API وابسته است.
4.25.2.1 پروفایلر CPU #
پروفایلر CPU در Go میتواند به شما کمک کند تا قسمتهایی از کد خود را که زمان CPU زیادی مصرف میکنند، شناسایی کنید.
⚠️ توجه داشته باشید که زمان CPU معمولاً با زمان واقعی که کاربران شما تجربه میکنند (که به آن تاخیر میگویند) متفاوت است. به عنوان مثال، یک درخواست HTTP معمولاً ممکن است ۱۰۰ میلیثانیه طول بکشد، اما تنها ۵ میلیثانیه از زمان CPU را مصرف کند و ۹۵ میلیثانیه را در انتظار پاسخ از پایگاه داده بگذراند. همچنین ممکن است یک درخواست ۱۰۰ میلیثانیه طول بکشد، اما ۲۰۰ میلیثانیه از زمان CPU را صرف کند اگر دو goroutine به طور همزمان کارهای پردازشی سنگین انجام دهند. اگر این موضوع برای شما گیجکننده است.
شما میتوانید پروفایلر CPU را از طریق APIهای مختلف کنترل کنید:
go test -cpuprofile cpu.pprof: این دستور تستهای شما را اجرا کرده و پروفایل CPU را در فایلی به نام cpu.pprof مینویسد.pprof.StartCPUProfile(w): این دستور پروفایل CPU را به w ضبط میکند و زمان را تا زمانی کهpprof.StopCPUProfile()فراخوانی شود، پوشش میدهد.import _ "net/http/pprof": این کد به شما اجازه میدهد با درخواست GET به آدرس/debug/pprof/profile?seconds=30از سرور HTTP پیشفرض که میتوانید با استفاده ازhttp.ListenAndServe("localhost:6060", nil)راهاندازی کنید، یک پروفایل CPU به مدت ۳۰ ثانیه درخواست کنید.runtime.SetCPUProfileRate(): این تابع به شما اجازه میدهد نرخ نمونهگیری پروفایلر CPU را کنترل کنید. برای محدودیتهای فعلی به محدودیتهای پروفایلر CPU مراجعه کنید.runtime.SetCgoTraceback(): این تابع میتواند برای دریافت ردیابیهای پشته به کد cgo استفاده شود.benesch/cgosymbolizerیک پیادهسازی برای Linux و macOS دارد.
اگر به یک قطعه کد سریع نیاز دارید که بتوانید در تابع main() خود قرار دهید، میتوانید از کد زیر استفاده کنید:
file, _ := os.Create("./cpu.pprof")
pprof.StartCPUProfile(file)
defer pprof.StopCPUProfile()
صرف نظر از اینکه چگونه پروفایلر CPU را فعال میکنید، پروفایل بهدستآمده در اصل یک جدول از ردیابیهای پشته است که به فرمت باینری pprof قالببندی شده است. در زیر نسخهای سادهشده از چنین جدولی نشان داده شده است:
| stack trace | samples/count | cpu/nanoseconds |
|---|---|---|
| main;foo | 5 | 50000000 |
| main;foo;bar | 3 | 30000000 |
| main;foobar | 4 | 40000000 |
پروفایلر CPU این دادهها را با درخواست از سیستمعامل برای نظارت بر استفاده از CPU برنامه جمعآوری میکند و هر ۱۰ میلیثانیه که CPU زمانی را مصرف میکند، سیگنال SIGPROF را به آن ارسال میکند. همچنین سیستمعامل زمان صرفشده توسط کرنل به نمایندگی از برنامه را در این نظارت شامل میکند. از آنجا که نرخ تحویل سیگنال به مصرف CPU وابسته است، این نرخ دینامیک بوده و میتواند به حداکثر N * 100Hz برسد که در آن N تعداد هستههای منطقی CPU در سیستم است.
هنگامی که سیگنال SIGPROF دریافت میشود، هندلر سیگنال Go یک ردیابی پشته از goroutine فعالی که در حال حاضر در حال اجرا است، جمعآوری میکند و مقادیر مربوطه در پروفایل را افزایش میدهد. مقدار cpu/nanoseconds در حال حاضر مستقیماً از تعداد نمونهها مشتق میشود، بنابراین این مقدار تکراری است، اما راحت است.
4.25.2.1.1 برچسبهای پروفایلر (Profiler Labels) CPU #
یکی از ویژگیهای جالب پروفایلر CPU در Go این است که میتوانید جفتهای کلید و مقدار دلخواهی را به یک goroutine متصل کنید. این برچسبها توسط هر goroutineای که از آن goroutine متولد میشود، به ارث برده میشوند و در پروفایل نهایی نمایش داده میشوند.
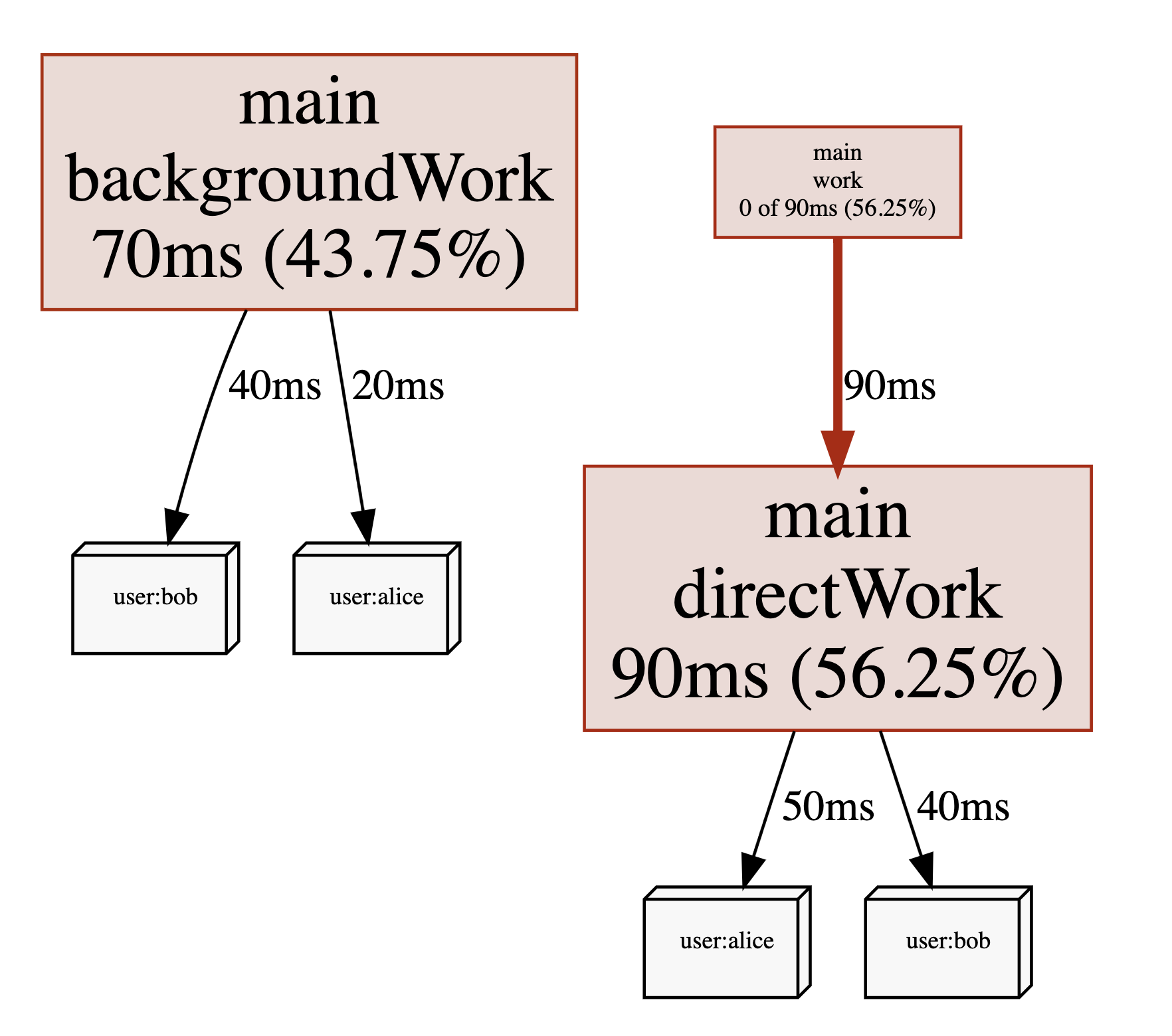
بیایید مثالی را در نظر بگیریم که برخی از کارهای CPU را به نمایندگی از یک کاربر انجام میدهد. با استفاده از API های pprof.Labels() و pprof.Do()، میتوانیم کاربر را با goroutine که در حال اجرای تابع work() است، مرتبط کنیم. علاوه بر این، برچسبها بهطور خودکار توسط هر goroutineای که در همان بلوک کد متولد میشود، به ارث برده میشوند، برای مثال goroutine backgroundWork().
func work(ctx context.Context, user string) {
labels := pprof.Labels("user", user)
pprof.Do(ctx, labels, func(_ context.Context) {
go backgroundWork()
directWork()
})
}
پروفایل نهایی شامل یک ستون برچسب جدید خواهد بود و ممکن است به شکل زیر باشد:
| stack trace | label | samples/count | cpu/nanoseconds |
|---|---|---|---|
| main.backgroundWork | user:bob | 5 | 50000000 |
| main.backgroundWork | user:alice | 2 | 20000000 |
| main.work;main.directWork | user:bob | 4 | 40000000 |
| main.work;main.directWork | user:alice | 3 | 30000000 |
مشاهده همان پروفایل با نمای گراف pprof نیز شامل برچسبها خواهد بود:
چگونگی استفاده از این برچسبها به شما بستگی دارد. میتوانید مواردی مانند شناسههای کاربری، شناسههای درخواست، نقاط پایانی HTTP، برنامههای اشتراک یا دادههای دیگر را شامل کنید که به شما کمک میکند درک بهتری از اینکه کدام نوع درخواستها باعث مصرف بالای CPU میشوند، حتی زمانی که توسط همان مسیرهای کد پردازش میشوند، به دست آورید. با این حال، استفاده از برچسبها اندازه فایلهای pprof شما را افزایش میدهد. بنابراین بهتر است با برچسبهای با کاردینالیته پایین مانند نقاط پایانی شروع کنید و سپس به برچسبهای با کاردینالیته بالا بروید، زمانی که احساس میکنید بر عملکرد برنامه شما تأثیر نمیگذارد.
⚠️ نسخههای Go 1.17 و پایینتر حاوی چندین اشکال بودند که میتوانستند منجر به عدم وجود برخی برچسبهای پروفایلر در پروفایلهای CPU شوند، برای اطلاعات بیشتر به محدودیتهای پروفایلر CPU مراجعه کنید.
4.25.2.1.2 مصرف CPU #
از آنجایی که نرخ نمونهگیری پروفایلر CPU با توجه به مقدار CPU که برنامه شما مصرف میکند، تنظیم میشود، میتوانید مصرف CPU را از پروفایلهای CPU استخراج کنید. در واقع، pprof این کار را به طور خودکار برای شما انجام میدهد. به عنوان مثال، پروفایل زیر از برنامهای استخراج شده است که دارای میانگین مصرف CPU برابر با 147.77% بود:
$ go tool pprof guide/cpu-utilization.pprof
Type: cpu
Time: Sep 9, 2021 at 11:34pm (CEST)
Duration: 1.12s, Total samples = 1.65s (147.77%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)
روش دیگری که برای بیان مصرف CPU محبوب است، استفاده از هستههای CPU است. در مثال بالا، برنامه بهطور میانگین از 1.47 هسته CPU در طول دوره پروفایلسازی استفاده میکرد.
⚠️ در نسخههای Go 1.17 و پایینتر، نباید به این عدد به خصوص اگر نزدیک یا بیشتر از 250% باشد، اعتماد زیادی داشته باشید. با این حال، اگر عدد بسیار پایینی مانند 10% مشاهده کردید، معمولاً نشاندهنده این است که مصرف CPU برای برنامه شما مشکلی نیست. یک اشتباه رایج این است که به این عدد توجه نکرده و نگران یک تابع خاص باشید که زمان زیادی نسبت به بقیه پروفایل صرف میکند. این معمولاً وقت تلف کردن است، زمانی که مصرف کلی CPU پایین است، زیرا از بهینهسازی این تابع چندان سودی نخواهید برد.
4.25.2.1.3 فراخوانیهای سیستم در پروفایلهای CPU #
اگر در پروفایلهای CPU خود فراخوانیهای سیستمی مانند syscall.Read() یا syscall.Write() را مشاهده کردید که زمان زیادی را صرف میکنند، لطفاً توجه داشته باشید که این فقط زمان CPU صرف شده در داخل این توابع در هسته است. زمان I/O خود بهطور جداگانه پیگیری نمیشود. صرف زمان زیادی در فراخوانیهای سیستمی معمولاً نشانهای از انجام بیش از حد آنها است، بنابراین شاید افزایش اندازه بافرها بتواند کمک کند. برای موقعیتهای پیچیدهتر مانند این، باید استفاده از Linux perf را در نظر بگیرید، زیرا میتواند stack trace های هسته را نیز به شما نشان دهد که ممکن است سرنخهای اضافی برای شما فراهم کند.
4.25.2.1.4 محدودیتهای پروفایلر CPU #
چندین مشکل و محدودیت شناختهشده برای پروفایلر CPU وجود دارد که ممکن است بخواهید از آنها آگاه باشید:
🐞 GH #35057: پروفایلهای CPU که با نسخههای Go <= 1.17 گرفته شدهاند، بهطور نسبی برای برنامههایی که از بیش از 2.5 هسته CPU استفاده میکنند، دقت کمتری دارند. بهطور کلی، استفاده کلی از CPU بهطور نادرست گزارش میشود و پیکهای بارکاری ممکن است بهدرستی در پروفایل حاصل نمایان نشوند. این مشکل در Go 1.18 برطرف شده است. در عین حال، میتوانید از Linux perf بهعنوان یک راهحل موقت استفاده کنید.
🐞 برچسبهای پروفایلر در Go <= 1.17 از چندین باگ رنج میبردند.
- GH #48577 و CL 367200: برچسبها برای goroutineهایی که بر روی استک سیستم، کد C را اجرا میکنند یا فراخوانیهای سیستمی را انجام میدهند، گم شده بودند.
- CL 369741: اولین دسته از نمونهها در یک پروفایل CPU دارای خطای off-by-one بودند که باعث نسبتگذاری نادرست برچسبها میشد.
- CL 369983: سیستم goroutineهایی که به نمایندگی از goroutineهای کاربر ایجاد شدهاند (مثلاً برای جمعآوری زباله) بهطور نادرست برچسبهای والدین خود را به ارث بردند.
⚠️️ میتوانید از
runtime.SetCPUProfileRate()برای تنظیم نرخ پروفایلر CPU قبل از فراخوانیruntime.StartCPUProfile()استفاده کنید. این عمل یک هشدار را چاپ میکند که میگویدruntime: cannot set cpu profile rate until previous profile has finished. با این حال، این عمل هنوز در چارچوب محدودیتهای باگ ذکر شده عمل میکند. این مسئله ابتدا در اینجا مطرح شد و یک پیشنهاد پذیرفته شده برای بهبود API وجود دارد.⚠️ حداکثر تعداد فراخوانیهای تو در توی تابعی که میتواند در stack trace ها توسط پروفایلر CPU ضبط شود، در حال حاضر 64 است. اگر برنامه شما از الگوهایی مانند بازگشت عمیق یا دیگر الگوهایی استفاده کند که به عمق استک بالایی منجر میشود، پروفایل CPU شما شامل stack trace هایی خواهد بود که برش داده شدهاند. این به این معناست که شما بخشی از زنجیرهٔ فراخوانی که به تابعی که در زمان نمونهبرداری فعال بود، منجر شده، را از دست خواهید داد.
4.25.2.2 پروفایلر حافظه (Memory) #
پروفایلر حافظه در Go میتواند به شما کمک کند تا شناسایی کنید کدام بخشهای کد شما دارای تعداد زیادی تخصیصات حافظه در هیپ (heap) هستند و همچنین چند تا از این تخصیصات در آخرین جمعآوری زباله (garbage collection) هنوز در دسترس بودند. به همین دلیل، پروفایل تولید شده توسط پروفایلر حافظه معمولاً بهعنوان پروفایل هیپ نیز شناخته میشود.
مدیریت حافظه هیپ معمولاً مسئول حدود 20-30% از زمان CPU مصرفی توسط فرآیندهای Go است. علاوه بر این، حذف تخصیصات هیپ میتواند تأثیرات ثانویهای داشته باشد که بخشهای دیگر کد شما را بهدلیل کاهش مقدار هدر رفت کش (cache thrashing) که در هنگام اسکن هیپ توسط جمعآورنده زباله (garbage collector) رخ میدهد، سریعتر میکند. به این معنی که بهینهسازی تخصیصهای حافظه میتواند معمولاً بازگشت بهتری نسبت به بهینهسازی مسیرهای کد وابسته به CPU در برنامه شما داشته باشد.
⚠️ پروفایلر حافظه تخصیصات استک را نشان نمیدهد زیرا اینها بهطور کلی بسیار ارزانتر از تخصیصات هیپ هستند. برای اطلاعات بیشتر به بخش جمعآورنده زباله مراجعه کنید.
شما میتوانید پروفایلر حافظه را از طریق API های مختلف کنترل کنید:
go test -memprofile mem.pprofتستهای شما را اجرا میکند و پروفایل حافظه را در فایلی به نامmem.pprofمینویسد.pprof.Lookup("allocs").WriteTo(w, 0)پروفایل حافظهای که شامل رویدادهای تخصیص از زمان شروع فرآیند است را بهwمینویسد.import _ "net/http/pprof"به شما امکان میدهد که یک پروفایل حافظه 30 ثانیهای با فراخوانیGET /debug/pprof/allocs?seconds=30از سرور HTTP پیشفرض که میتوانید باhttp.ListenAndServe("localhost:6060", nil)راهاندازی کنید، درخواست کنید. این پروفایل بهطور داخلی به عنوان پروفایل دلتا (delta profile) شناخته میشود.runtime.MemProfileRateبه شما اجازه میدهد تا نرخ نمونهبرداری پروفایلر حافظه را کنترل کنید. برای محدودیتهای کنونی به محدودیتهای پروفایلر حافظه مراجعه کنید.
اگر به یک قطعه کد سریع نیاز دارید که بتوانید آن را به تابع main() خود اضافه کنید، میتوانید از کد زیر استفاده کنید:
file, _ := os.Create("./mem.pprof")
defer pprof.Lookup("allocs").WriteTo(file, 0)
defer runtime.GC()
صرف نظر از اینکه چگونه پروفایلر حافظه را فعال کنید، پروفایل حاصل اساساً یک جدول از ردیابیهای پشته است که به فرمت باینری pprof فرمتبندی شده است. نسخهای سادهشده از چنین جدولی در زیر نشان داده شده است:
| stack trace | alloc_objects/count | alloc_space/bytes | inuse_objects/count | inuse_space/bytes |
|---|---|---|---|---|
| main;foo | 5 | 120 | 2 | 48 |
| main;foo;bar | 3 | 768 | 0 | 0 |
| main;foobar | 4 | 512 | 1 | 128 |
یک پروفایل حافظه شامل دو بخش اصلی اطلاعات است:
alloc_*: مقدار تخصیصهایی که برنامه شما از زمان شروع فرایند (یا دوره پروفایلگیری برای پروفایلهای دلتا) انجام داده است.inuse_*: مقدار تخصیصهایی که برنامه شما انجام داده و در آخرین جمعآوری زباله (GC) همچنان قابل دسترسی بودند.
شما میتوانید از این اطلاعات برای مقاصد مختلف استفاده کنید. به عنوان مثال، میتوانید از دادههای alloc_* برای تعیین اینکه کدام مسیرهای کد ممکن است زباله زیادی تولید کنند که GC باید با آن برخورد کند، استفاده کنید. همچنین بررسی دادههای inuse_* در طول زمان میتواند به شما در بررسی نشت حافظه یا استفاده بالای حافظه توسط برنامهتان کمک کند.
4.25.2.2.1 تفاوت پروفایلهای Allocations و Heap #
تابع pprof.Lookup() و همچنین بسته [net/http/pprof](https://pkg.go.dev/net/http/pprof) پروفایل حافظه را تحت دو نام مختلف عرضه میکنند: allocs و heap. هر دو پروفایل شامل دادههای یکسانی هستند، تنها تفاوت این است که پروفایل allocs به عنوان نوع نمونه پیشفرض alloc_space/bytes را دارد، در حالی که پروفایل heap به طور پیشفرض inuse_space/bytes را انتخاب میکند. این موضوع توسط ابزار pprof برای تصمیمگیری درباره نوع نمونهای که باید به طور پیشفرض نشان داده شود، استفاده میشود.
4.25.2.2.2 نمونهبرداری (Sampling) پروفایل حافظه #
برای حفظ بار کم، پروفایل حافظه از نمونهبرداری پواسون استفاده میکند تا به طور متوسط فقط یک تخصیص از هر 512KiB باعث شود که یک ردیابی پشته گرفته شده و به پروفایل اضافه شود. با این حال، قبل از اینکه پروفایل به فایل نهایی pprof نوشته شود، زماناجرا مقادیر نمونه جمعآوری شده را با تقسیم بر احتمال نمونهبرداری مقیاس میدهد. این بدان معناست که مقدار تخصیصهای گزارش شده باید تخمینی خوب از مقدار واقعی تخصیصها باشد، صرفنظر از نرخ runtime.MemProfileRate که استفاده میکنید.
برای پروفایلگیری در محیط تولید، معمولاً نیازی به تغییر نرخ نمونهبرداری نیست. تنها دلیلی که برای این کار وجود دارد، نگرانی درباره این است که در شرایطی که تخصیصهای بسیار کمی انجام میشود، ممکن است تعداد کافی نمونهها جمعآوری نشود.
4.25.2.2.3 Memory Inuse در مقابل RSS #
یک اشتباه رایج این است که مقدار کل حافظه گزارششده توسط نوع نمونه inuse_space/bytes را با مقدار استفاده از حافظه RSS که توسط سیستمعامل گزارش میشود مقایسه کنید و متوجه شوید که این دو با هم مطابقت ندارند. دلایل مختلفی برای این عدم تطابق وجود دارد:
- بهطور تعریف شده، RSS شامل مواردی بیشتر از فقط استفاده از حافظه پشته Go است، مانند حافظه استفاده شده توسط پشتههای گوروتینها، فایل اجرایی برنامه، کتابخانههای مشترک و همچنین حافظه تخصیص یافته توسط توابع C.
- GC (جمعکننده زباله) ممکن است تصمیم بگیرد که حافظه آزاد را فوراً به سیستمعامل بازنگرداند، اما بعد از تغییرات زماناجرا در Go 1.16 این موضوع کمتر مشکلساز شده است.
- Go از GC غیرمتحرک استفاده میکند، بنابراین در برخی موارد، حافظه آزاد پشته ممکن است به گونهای تکهتکه شود که مانع از بازگشت آن به سیستمعامل شود.
4.25.2.2.4 پیادهسازی پروفایلر حافظه #
کد زیر باید جنبههای اساسی پیادهسازی پروفایلر حافظه را پوشش دهد تا شما درک بهتری از آن داشته باشید. همانطور که مشاهده میکنید، تابع malloc() در داخل زماناجرای Go از تابع poisson_sample(size) برای تعیین این که آیا باید یک تخصیص نمونهگیری شود یا خیر استفاده میکند. اگر جواب مثبت باشد، یک دنباله پشته (stack trace) به نام s گرفته میشود و به عنوان کلید در mem_profile (یک نقشه هش) استفاده میشود تا شمارندههای allocs و alloc_bytes افزایش یابند. علاوه بر این، فراخوانی track_profiled(object, s)، شیء تخصیص یافته را به عنوان یک تخصیص نمونهگیری شده در پشته علامتگذاری میکند و دنباله پشته s را با آن مرتبط میسازد.
func malloc(size):
object = ... // allocation magic
if poisson_sample(size):
s = stacktrace()
mem_profile[s].allocs++
mem_profile[s].alloc_bytes += size
track_profiled(object, s)
return object
هنگامی که GC (جمعآوری زبالهها) تعیین میکند که زمان آزادسازی یک شیء تخصیص یافته فرا رسیده است، تابع sweep() را فراخوانی میکند که از is_profiled(object) استفاده میکند تا بررسی کند آیا شیء به عنوان یک شیء نمونهگیری شده علامتگذاری شده است یا خیر. اگر جواب مثبت باشد، دنباله پشته s که منجر به تخصیص شده بود بازیابی میشود و شمارندههای frees و free_bytes برای آن داخل mem_profile افزایش مییابد.
func sweep(object):
if is_profiled(object)
s = alloc_stacktrace(object)
mem_profile[s].frees++
mem_profile[s].free_bytes += sizeof(object)
// deallocation magic
شمارندههای free_* بهطور مستقیم در پروفایل نهایی حافظه گنجانده نمیشوند. در عوض، از آنها برای محاسبه شمارندههای inuse_* در پروفایل از طریق کم کردن سادهی frees از allocs استفاده میشود. همچنین، مقادیر خروجی نهایی با تقسیم آنها بر احتمال نمونهگیری مقیاسبندی میشوند.
4.25.2.2.5 محدودیتهای پروفایلر حافظه #
چندین مشکل و محدودیت شناختهشده برای پروفایلر حافظه وجود دارد که باید از آنها آگاه باشید:
- 🐞 GH #49171: پروفایلهای دلتا (که با مثلاً
GET /debug/pprof/allocs?seconds=60گرفته میشوند) ممکن است به دلیل یک باگ در همنمادسازی مرتبط با closures داخلی در Go 1.17 شمارش تخصیص منفی را گزارش کنند. این مشکل در Go 1.18 رفع شده است. - ⚠️
runtime.MemProfileRateباید فقط یک بار و در اسرع وقت در ابتدای اجرای برنامه تغییر داده شود؛ برای مثال در ابتدای تابعmain(). تغییر این مقدار بهصورت چندباره در طول اجرای برنامه باعث تولید پروفایلهای نادرست خواهد شد. - ⚠ هنگام عیبیابی نشتیهای حافظه احتمالی، پروفایلر حافظه میتواند نشان دهد که این تخصیصها کجا ایجاد شدهاند، اما نمیتواند نشان دهد که کدام مراجع باعث زنده نگهداشتن آنها هستند. چندین تلاش برای حل این مشکل انجام شده است، اما هیچکدام با نسخههای اخیر Go کار نمیکنند.
- ⚠ برچسبهای پروفایلر CPU یا مشابه آن توسط پروفایلر حافظه پشتیبانی نمیشوند. اضافه کردن این ویژگی به پیادهسازی فعلی سخت است زیرا میتواند منجر به نشتی حافظه در جدول هش داخلی دادههای پروفایل حافظه شود.
- ⚠ تخصیصهای انجام شده توسط کد C (cgo) در پروفایل حافظه نمایش داده نمیشوند.
- ⚠ دادههای پروفایل حافظه ممکن است تا دو چرخهی جمعآوری زباله قدیمی باشند. اگر نیاز به یک عکس فوری مداوم دارید، میتوانید قبل از درخواست پروفایل حافظه،
runtime.GC()را فراخوانی کنید. net/http/pprof از آرگومان?gc=1برای این منظور پشتیبانی میکند. - ⚠ حداکثر تعداد توابع تو در تو که توسط پروفایلر حافظه در اثر فراخوانی ثبت میشوند، در حال حاضر
32است. برای اطلاعات بیشتر در مورد این محدودیت، به محدودیتهای پروفایلر CPU مراجعه کنید. - ⚠ هیچ محدودیتی برای اندازهی جدول هش داخلی که پروفایل حافظه را نگه میدارد وجود ندارد. این جدول تا زمانی که تمام مسیرهای تخصیص کد شما را پوشش دهد، بزرگ میشود. این مسئله در عمل مشکلساز نیست اما ممکن است بهنظر برسد که مانند یک نشتی حافظه کوچک است اگر از میزان استفاده حافظه فرآیند خود نظارت کنید.
4.25.2.3 پروفایلر بلاک #
پروفایلر بلاک در Go اندازهگیری میکند که چقدر زمان گوروتینهای شما در حالت Off-CPU صرف میشود، در حالی که منتظر عملیات کانال و mutexهای ارائهشده توسط پکیج sync هستند. عملیاتهای Go زیر توسط پروفایلر بلاک کنترل میشوند:
- select
- chan send
- chan receive
- semacquire (مثل
Mutex.Lock،RWMutex.RLock،RWMutex.Lock،WaitGroup.Wait) - notifyListWait (مثل
Cond.Wait)
⚠️ پروفایلهای بلاک شامل زمان انتظار روی I/O، خواب (Sleep)، GC و سایر حالات انتظار نیستند. همچنین رویدادهای مسدود کننده تا زمانی که کامل نشوند ثبت نمیشوند، بنابراین پروفایل بلاک نمیتواند برای اشکالزدایی از اینکه چرا یک برنامه Go در حال حاضر قفل کرده استفاده شود. برای این منظور، از پروفایلر گوروتین میتوان استفاده کرد.
4.25.2.3.1 کنترل پروفایلر بلاک با APIهای مختلف: #
- دستور
go test -blockprofile block.pprofتستها را اجرا کرده و پروفایلی از هر رویداد مسدودکننده در فایلی به نامblock.pprofذخیره میکند. - تابع
runtime.SetBlockProfileRate(rate)به شما اجازه میدهد نرخ نمونهگیری پروفایلر بلاک را کنترل کنید. - دستور
pprof.Lookup("block").WriteTo(w, 0)پروفایلی از رویدادهای مسدودکننده از ابتدای فرآیند تا کنون ایجاد میکند و در خروجیwمینویسد. - دستور
import _ "net/http/pprof"اجازه میدهد تا با استفاده از درخواستGET /debug/pprof/block?seconds=30یک پروفایل بلاک 30 ثانیهای درخواست کنید.
4.25.2.3.2 کد نمونه برای استفاده از پروفایلر بلاک در برنامه: #
runtime.SetBlockProfileRate(100_000_000) // هشدار: میتواند باعث افزایش استفاده از CPU شود
file, _ := os.Create("./block.pprof")
defer pprof.Lookup("block").WriteTo(file, 0)
صرفنظر از نحوه فعال کردن پروفایلر بلاک، پروفایل نهایی یک جدول از ردپاهای پشته خواهد بود که در فرمت باینری pprof فرمت شده است.
| stack trace | contentions/count | delay/nanoseconds |
|---|---|---|
| main;foo;runtime.selectgo | 5 | 867549417 |
| main;foo;bar;sync.(*Mutex).Lock | 3 | 453510869 |
| main;foobar;runtime.chanrecv1 | 4 | 5351086 |
4.25.2.3.3 پیادهسازی پروفایلر بلاک #
کد شبه زیر جنبههای اساسی از پیادهسازی پروفایلر بلاک را نشان میدهد تا درک بهتری از آن به شما بدهد. هنگام ارسال پیام به یک کانال، یعنی ch <- msg، Go تابع chansend() را در runtime فراخوانی میکند. اگر کانال برای دریافت پیام آماده باشد (ready())، عملیات send() بلافاصله انجام میشود. در غیر این صورت، پروفایلر بلاک زمان شروع رویداد مسدودکننده را ثبت میکند و از تابع wait_until_ready() استفاده میکند تا گوروتین از CPU خارج شود تا زمانی که کانال آماده شود. هنگامی که کانال آماده شد، مدت زمان مسدود شدن تعیین میشود و با استفاده از تابع random_sample() و نرخ نمونهگیری، بررسی میشود که آیا باید این رویداد مسدودکننده ثبت شود یا خیر. در صورت مثبت بودن پاسخ، ردپای پشته فعلی (stack trace) گرفته شده و به عنوان کلید درون نقشه هش block_profile استفاده میشود تا شمارندههای count و delay افزایش یابند. پس از آن، عملیات send() ادامه مییابد.
func chansend(channel, msg):
if ready(channel):
send(channel, msg)
return
start = now()
wait_until_ready(channel) // Off-CPU Wait
duration = now() - start
if random_sample(duration, rate):
s = stacktrace()
// note: actual implementation is a bit trickier to correct for bias
block_profile[s].contentions += 1
block_profile[s].delay += duration
send(channel, msg)
تابع random_sample به این صورت عمل میکند. اگر پروفایلر بلاک فعال باشد، همه رویدادهایی که duration >= rate باشند ثبت میشوند و رویدادهای کوتاهتر با احتمال duration/rate ثبت میشوند.
func random_sample(duration, rate):
if rate <= 0 || (duration < rate && duration/rate > rand(0, 1)):
return false
return true
به عبارت دیگر، اگر نرخ (rate) را برابر 10,000 تنظیم کنید (واحد در اینجا نانوثانیه است)، همه رویدادهای مسدودکنندهای که 10 µsec یا بیشتر طول میکشند ثبت میشوند. علاوه بر این، 10% از رویدادهای با طول 1 µsec و 1% از رویدادهای با طول 100 نانوثانیه و… نیز ثبت میشوند.
4.25.2.3.4 تفاوت پروفایلر بلاک و پروفایلر Mutex #
هر دو پروفایلر بلاک و mutex زمان انتظار روی mutexها را گزارش میدهند. تفاوت این است که پروفایلر بلاک زمان انتظار برای به دست آوردن Lock() را ثبت میکند، در حالی که پروفایلر mutex زمانی که گوروتین دیگری منتظر Unlock() است تا اجرا شود را ثبت میکند.
4.25.2.3.5 محدودیتهای پروفایلر بلاک #
- 🚨 پروفایلر بلاک میتواند باعث افزایش قابل توجه مصرف CPU در محیط تولید شود. توصیه میشود که تنها برای توسعه و تست استفاده شود. اگر نیاز به استفاده از آن در محیط تولید دارید، با نرخ بسیار بالا شروع کنید، مثلاً 100 میلیون، و تنها در صورت نیاز آن را کاهش دهید.
- ⚠ پروفایلهای بلاک تنها شامل زیر مجموعه کوچکی از حالات انتظار Off-CPU هستند که یک گوروتین میتواند وارد آنها شود.
- ⚠ حداکثر تعداد توابع تو در تو که میتوانند در ردپاهای پشته توسط پروفایلر بلاک ثبت شوند، فعلاً برابر
32است. - ⚠ نقشه هش داخلی که پروفایل بلاک را نگه میدارد هیچ محدودیتی در اندازه ندارد.
4.25.2.4 پروفایلر Mutex #
پروفایلر mutex زمانی را اندازهگیری میکند که گوروتینها صرف مسدود کردن سایر گوروتینها میکنند. به عبارتی، این پروفایلر منابع رقابت برای قفلها را ثبت میکند. پروفایلر mutex میتواند رقابت ناشی از sync.Mutex و sync.RWMutex را ثبت کند.
⚠️ پروفایلهای mutex شامل سایر منابع رقابت مثل sync.WaitGroup، sync.Cond یا دسترسی به توصیفکنندههای فایل نمیشوند. همچنین، رقابت mutex تا زمانی که mutex آزاد نشود، ثبت نمیشود. بنابراین، پروفایل mutex برای اشکالزدایی از دلیل معلق بودن برنامه Go قابل استفاده نیست؛ برای این کار میتوانید از پروفایلر گوروتین استفاده کنید.
4.25.2.4.1 کنترل پروفایلر Mutex #
چندین API برای کنترل پروفایلر mutex در دسترس است:
go test -mutexprofile mutex.pprofتستها را اجرا میکند و پروفایل mutex را در یک فایل با نامmutex.pprofمینویسد.runtime.SetMutexProfileRate(rate)به شما امکان میدهد نرخ نمونهگیری پروفایلر mutex را فعال و کنترل کنید. اگر نرخ نمونهگیری برابر باRتنظیم شود، به طور متوسط1/Rاز رویدادهای رقابت mutex ثبت میشوند. اگر نرخ برابر 0 یا کمتر باشد، هیچ رویدادی ثبت نمیشود.pprof.Lookup("mutex").WriteTo(w, 0)پروفایل mutex را از شروع پردازش تا زمان نوشتن بهwثبت میکند.import _ "net/http/pprof"به شما امکان میدهد با ارسال درخواست به مسیرGET /debug/pprof/mutex?seconds=30یک پروفایل 30 ثانیهای از mutexها دریافت کنید.
4.25.2.4.2 نمونه سریع استفاده از پروفایلر Mutex #
اگر نیاز به کد سریع برای قرار دادن در تابع main() دارید، میتوانید از کد زیر استفاده کنید:
runtime.SetMutexProfileFraction(100)
file, _ := os.Create("./mutex.pprof")
defer pprof.Lookup("mutex").WriteTo(file, 0)
پروفایل mutex به دست آمده در اصل جدولی از ردپای پشتهها (stack traces) خواهد بود که به صورت فرمت دودویی pprof ذخیره میشود.
| stack trace | contentions/count | delay/nanoseconds |
|---|---|---|
| main;foo;sync.(*Mutex).Unlock | 5 | 867549417 |
| main;bar;baz;sync.(*Mutex).Unlock | 3 | 453510869 |
| main;foobar;sync.(*RWMutex).RUnlock | 4 | 5351086 |
4.25.2.4.3 تفاوت پروفایلهای Block و Mutex #
پروفایلهای block و mutex هر دو زمان انتظار روی mutexها را ثبت میکنند، اما تفاوت در این است که پروفایل block زمانی که گوروتین در حال انتظار برای قفل شدن است را ثبت میکند، در حالی که پروفایل mutex زمانی که یک گوروتین قفل را در اختیار دارد و باعث جلوگیری از ادامه کار سایر گوروتینها میشود، را ثبت میکند.
4.25.2.4.4 پیادهسازی پروفایلر Mutex #
پروفایلر mutex با ثبت زمانی که یک گوروتین تلاش میکند قفلی را بگیرد (مثلاً mu.Lock())، تا زمانی که گوروتین صاحب قفل آن را آزاد کند (مثلاً mu.Unlock())، کار میکند. ابتدا یک گوروتین semacquire() را برای گرفتن قفل فراخوانی میکند و اگر قفل در حال حاضر توسط گوروتین دیگری گرفته شده باشد، زمان شروع انتظار ثبت میشود. وقتی گوروتین صاحب قفل آن را با فراخوانی semrelease() آزاد میکند، گوروتین منتظر بررسی میشود و زمان انتظار آن محاسبه میگردد. در نهایت، اگر رویداد به صورت تصادفی برای ثبت انتخاب شود، زمان مسدودی به یک نقشه هش (hash map) اضافه میشود که کلید آن پشته فراخوانی گوروتین آزادکننده قفل است.
4.25.2.4.5 محدودیتهای پروفایلر Mutex #
- ⚠️ حداکثر تعداد فراخوانیهای تو در تو که میتوان در پشته فراخوانیهای پروفایل mutex ثبت کرد، در حال حاضر
32است. برای اطلاعات بیشتر درباره محدودیتهای پروفایلر CPU، به مستندات مرتبط مراجعه کنید. - ⚠️ هیچ محدودیتی برای اندازه نقشه هش داخلی که دادههای پروفایل mutex را نگه میدارد وجود ندارد. این بدان معناست که اندازه آن تا زمانی که تمام مسیرهای مسدودکننده در کد شما پوشش داده شوند، رشد خواهد کرد. در عمل، این مشکل چندانی ایجاد نمیکند، اما ممکن است به عنوان یک نشت حافظه کوچک به نظر برسد.
- ⚠️ برچسبهای پروفایلر CPU در پروفایل mutex پشتیبانی نمیشوند. اضافه کردن این ویژگی به پیادهسازی فعلی ممکن است باعث ایجاد نشت حافظه در نقشه هش داخلی که دادههای پروفایل حافظه را نگه میدارد، شود.
- ⚠️ تعداد رقابتها و زمانهای تأخیر در یک پروفایل mutex بر اساس آخرین نرخ نمونهبرداری تنظیم شده، تنظیم میشوند، نه در زمان نمونهبرداری. در نتیجه، برنامههایی که نرخ نمونهبرداری پروفایل mutex را در میانه اجرای خود تغییر میدهند، ممکن است نتایج نادقیقی را مشاهده کنند.
4.25.2.5 پروفایلر Goroutine #
در زمان اجرای Go، تمام گوروتینها در یک آرایه ساده به نام allgs نگهداری میشوند. این آرایه شامل گوروتینهای فعال و غیرفعال (مرده) است. گوروتینهای مرده برای استفاده مجدد زمانی که گوروتینهای جدید ایجاد میشوند، نگه داشته میشوند.
Go دارای APIهای مختلفی برای بررسی گوروتینهای فعال در allgs است که به همراه استک ترِیس و برخی دیگر از ویژگیهای آنها اطلاعاتی ارائه میدهند. برخی از این APIها اطلاعات آماری ارائه میدهند، در حالی که برخی دیگر اطلاعات مربوط به هر گوروتین را به صورت جداگانه فراهم میکنند.
علیرغم تفاوتهای بین این APIها، تعریف مشترک از گوروتین “فعال” به نظر میرسد که شامل موارد زیر باشد:
- گوروتین از بین رفته نباشد.
- گوروتین سیستمی یا گوروتین نهاییکننده نباشد.
به عبارت دیگر، گوروتینهایی که در حال اجرا هستند و همچنین آنهایی که منتظر ورودی/خروجی (I/O)، قفلها، کانالها، برنامهریزی و غیره هستند، همه به عنوان “فعال” در نظر گرفته میشوند، حتی اگر به نظر برسد که برخی از این حالتها غیرفعال هستند.
4.25.2.5.1 سربار (Overhead) #
همه پروفایلگیریهای گوروتین در Go نیاز به یک فاز متوقفسازی جهان (stop-the-world) به اندازه O(N) دارند، که در آن N تعداد گوروتینهای تخصیص داده شده است. یک بنچمارک ساده نشان میدهد که جهان به طور تقریبی به ازای هر گوروتین حدود ~1µs متوقف میشود، وقتی از API runtime.GoroutineProfile() استفاده میشود. اما این مقدار ممکن است بسته به عواملی مانند عمق استک برنامه، تعداد گوروتینهای مرده و غیره تغییر کند.
به طور کلی، برنامههایی که بسیار حساس به تأخیر هستند و از هزاران گوروتین فعال استفاده میکنند، ممکن است بخواهند در پروفایلگیری گوروتین در محیط تولید با دقت بیشتری عمل کنند. با این حال، تعداد زیاد گوروتینها و حتی شاید خود زبان Go ممکن است برای چنین برنامههایی ایدهی مناسبی نباشد.
بیشتر برنامههایی که تعداد زیادی گوروتین ایجاد نمیکنند و میتوانند چند میلیثانیه تأخیر اضافی را تحمل کنند، نباید مشکلی با پروفایلگیری مستمر گوروتین در محیط تولید داشته باشند.
4.25.2.5.2 ویژگیهای گوروتین #
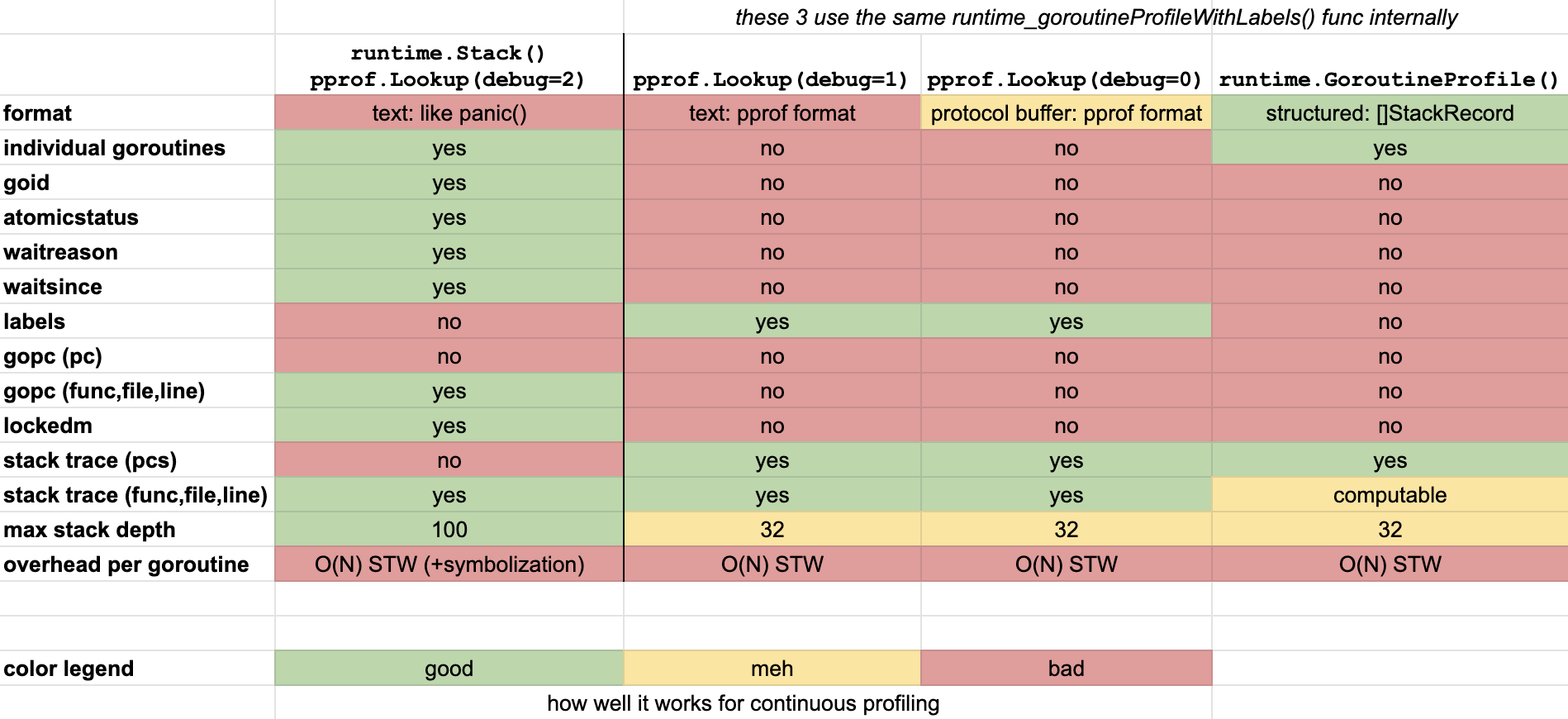
گوروتینها دارای بسیاری از ویژگیها هستند که میتوانند به اشکالزدایی برنامههای Go کمک کنند. موارد زیر جالب توجه هستند و به طرق مختلف از طریق APIهایی که در ادامه این سند توضیح داده شدهاند، در دسترس قرار دارند:
goid: شناسهی یکتای گوروتین؛ گوروتین اصلی دارای شناسه1است.atomicstatus: وضعیت گوروتین، یکی از موارد زیر:idle: تازه تخصیص داده شده است.runnable: در صف اجرا، منتظر زمانبندی.running: در حال اجرا روی یک نخ (thread) سیستمعامل.syscall: مسدود شده در یک فراخوان سیستمی.waiting: توسط زمانبندیکننده متوقف شده، نگاه کنید بهg.waitreason.dead: تازه خارج شده یا در حال دوبارهسازی.copystack: استک در حال انتقال است.preempted: تازه از اجرا خودداری کرده است.
waitreason: دلیلی که گوروتین در وضعیتwaitingقرار دارد، مانند خواب، عملیات کانال، I/O، جمعآوری زباله (GC) و غیره.waitsince: زمان تقریبی که گوروتین وارد وضعیتwaitingیاsyscallشده است که توسط اولین GC بعد از شروع انتظار تعیین میشود.labels: مجموعهای از کلید/مقدار برچسبهای پروفایلگیر که میتوانند به گوروتینها متصل شوند.stack trace: تابعی که در حال اجراست و همچنین توابع فراخواننده آن. این به صورت خروجی متنی شامل نام فایلها، نام توابع و شماره خطوط یا به صورت یک آرایه از آدرسهای شمارنده برنامه (PCs) نمایش داده میشود. 🚧تحقیق بیشتر درباره این موضوع: آیا میتوان متن تابع/فایل/خط را به PCs تبدیل کرد؟gopc: آدرس شمارنده برنامه (PC) مربوط به فراخوانیgo ...که باعث ایجاد این گوروتین شده است. این میتواند به فایل، نام تابع و شماره خط تبدیل شود.lockedm: نخی که این گوروتین به آن قفل شده است، در صورتی که وجود داشته باشد.
4.25.2.5.3 ماتریس ویژگیها (Feature Matrix) #
جدول ماتریس ویژگیهای زیر به شما یک ایده کلی از دسترسی کنونی این ویژگیها از طریق APIهای مختلف ارائه میدهد.
4.25.2.5.4 APIها #
runtime.Stack() / pprof.Lookup(debug=2)
این تابع خروجی متنی بدون ساختار بازمیگرداند که شامل استک (Stack) تمام گوروتینهای فعال و ویژگیهایی که در ماتریس ویژگیها ذکر شده است، میباشد.
ویژگی waitsince به عنوان nanotime() - gp.waitsince() بر حسب دقیقه نمایش داده میشود، اما تنها زمانی که مدت زمان بیش از 1 دقیقه باشد.
pprof.Lookup(debug=2) یک نام مستعار سادهشده برای استفاده از این پروفایل است. فراخوانی واقعی به این شکل است:
profile := pprof.Lookup("goroutine")
profile.WriteTo(os.Stdout, 2)
پیادهسازی پروفایل به سادگی runtime.Stack() را فراخوانی میکند.
در زیر مثالی کوتاه از خروجی بازگردانده شده آمده است.
goroutine 1 [running]:
main.glob..func1(0x14e5940, 0xc0000aa7b0, 0xc000064eb0, 0x2)
/Users/felix.geisendoerfer/go/src/github.com/felixge/go-profiler-notes/examples/goroutine/main.go:29 +0x6f
main.writeProfiles(0x2, 0xc0000c4008, 0x1466424)
/Users/felix.geisendoerfer/go/src/github.com/felixge/go-profiler-notes/examples/goroutine/main.go:106 +0x187
main.main()
/Users/felix.geisendoerfer/go/src/github.com/felixge/go-profiler-notes/examples/goroutine/main.go:152 +0x3d2
goroutine 22 [sleep, 1 minutes]:
time.Sleep(0x3b9aca00)
/usr/local/Cellar/go/1.15.6/libexec/src/runtime/time.go:188 +0xbf
main.shortSleepLoop()
/Users/felix.geisendoerfer/go/src/github.com/felixge/go-profiler-notes/examples/goroutine/main.go:165 +0x2a
created by main.indirectShortSleepLoop2
/Users/felix.geisendoerfer/go/src/github.com/felixge/go-profiler-notes/examples/goroutine/main.go:185 +0x35
goroutine 3 [IO wait, 1 minutes]:
internal/poll.runtime_pollWait(0x1e91e88, 0x72, 0x0)
/usr/local/Cellar/go/1.15.6/libexec/src/runtime/netpoll.go:222 +0x55
internal/poll.(*pollDesc).wait(0xc00019e018, 0x72, 0x0, 0x0, 0x1465786)
/usr/local/Cellar/go/1.15.6/libexec/src/internal/poll/fd_poll_runtime.go:87 +0x45
internal/poll.(*pollDesc).waitRead(...)
/usr/local/Cellar/go/1.15.6/libexec/src/internal/poll/fd_poll_runtime.go:92
internal/poll.(*FD).Accept(0xc00019e000, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0)
/usr/local/Cellar/go/1.15.6/libexec/src/internal/poll/fd_unix.go:394 +0x1fc
net.(*netFD).accept(0xc00019e000, 0x7d667d63cbbded3e, 0x1789ccbbded3e, 0x100000001)
/usr/local/Cellar/go/1.15.6/libexec/src/net/fd_unix.go:172 +0x45
net.(*TCPListener).accept(0xc000188060, 0x60006709, 0xc000196da8, 0x109abe6)
/usr/local/Cellar/go/1.15.6/libexec/src/net/tcpsock_posix.go:139 +0x32
net.(*TCPListener).Accept(0xc000188060, 0xc000196df8, 0x18, 0xc000001200, 0x12e9eec)
/usr/local/Cellar/go/1.15.6/libexec/src/net/tcpsock.go:261 +0x65
net/http.(*Server).Serve(0xc00019c000, 0x14ec6e0, 0xc000188060, 0x0, 0x0)
/usr/local/Cellar/go/1.15.6/libexec/src/net/http/server.go:2937 +0x266
net/http.(*Server).ListenAndServe(0xc00019c000, 0xc00019c000, 0x1475536)
/usr/local/Cellar/go/1.15.6/libexec/src/net/http/server.go:2866 +0xb7
net/http.ListenAndServe(...)
/usr/local/Cellar/go/1.15.6/libexec/src/net/http/server.go:3120
main.main.func1(0xc000032120)
/Users/felix.geisendoerfer/go/src/github.com/felixge/go-profiler-notes/examples/goroutine/main.go:123 +0x126
created by main.main
/Users/felix.geisendoerfer/go/src/github.com/felixge/go-profiler-notes/examples/goroutine/main.go:121 +0xc5
goroutine 4 [sleep, 1 minutes]:
time.Sleep(0x3b9aca00)
/usr/local/Cellar/go/1.15.6/libexec/src/runtime/time.go:188 +0xbf
main.shortSleepLoop()
/Users/felix.geisendoerfer/go/src/github.com/felixge/go-profiler-notes/examples/goroutine/main.go:165 +0x2a
created by main.main
/Users/felix.geisendoerfer/go/src/github.com/felixge/go-profiler-notes/examples/goroutine/main.go:130 +0x195
goroutine 5 [sleep, 1 minutes]:
time.Sleep(0x34630b8a000)
/usr/local/Cellar/go/1.15.6/libexec/src/runtime/time.go:188 +0xbf
main.sleepLoop(0x34630b8a000)
/Users/felix.geisendoerfer/go/src/github.com/felixge/go-profiler-notes/examples/goroutine/main.go:171 +0x2b
created by main.main
/Users/felix.geisendoerfer/go/src/github.com/felixge/go-profiler-notes/examples/goroutine/main.go:131 +0x1bc
goroutine 6 [chan receive, 1 minutes]:
main.chanReceiveForever()
/Users/felix.geisendoerfer/go/src/github.com/felixge/go-profiler-notes/examples/goroutine/main.go:177 +0x4d
created by main.main
/Users/felix.geisendoerfer/go/src/github.com/felixge/go-profiler-notes/examples/goroutine/main.go:132 +0x1d4
goroutine 24 [select, 1 minutes]:
net/http.(*persistConn).writeLoop(0xc0000cea20)
/usr/local/Cellar/go/1.15.6/libexec/src/net/http/transport.go:2340 +0x11c
created by net/http.(*Transport).dialConn
/usr/local/Cellar/go/1.15.6/libexec/src/net/http/transport.go:1709 +0xcdc
goroutine 23 [IO wait, 1 minutes]:
internal/poll.runtime_pollWait(0x1e91da0, 0x72, 0x14e6ca0)
/usr/local/Cellar/go/1.15.6/libexec/src/runtime/netpoll.go:222 +0x55
internal/poll.(*pollDesc).wait(0xc00010e198, 0x72, 0x14e6c00, 0x16db878, 0x0)
/usr/local/Cellar/go/1.15.6/libexec/src/internal/poll/fd_poll_runtime.go:87 +0x45
internal/poll.(*pollDesc).waitRead(...)
/usr/local/Cellar/go/1.15.6/libexec/src/internal/poll/fd_poll_runtime.go:92
internal/poll.(*FD).Read(0xc00010e180, 0xc000256000, 0x1000, 0x1000, 0x0, 0x0, 0x0)
/usr/local/Cellar/go/1.15.6/libexec/src/internal/poll/fd_unix.go:159 +0x1a5
net.(*netFD).Read(0xc00010e180, 0xc000256000, 0x1000, 0x1000, 0x103b1dc, 0xc000199b58, 0x10680e0)
/usr/local/Cellar/go/1.15.6/libexec/src/net/fd_posix.go:55 +0x4f
net.(*conn).Read(0xc000010008, 0xc000256000, 0x1000, 0x1000, 0x0, 0x0, 0x0)
/usr/local/Cellar/go/1.15.6/libexec/src/net/net.go:182 +0x8e
net/http.(*persistConn).Read(0xc0000cea20, 0xc000256000, 0x1000, 0x1000, 0xc00009e300, 0xc000199c58, 0x10074b5)
/usr/local/Cellar/go/1.15.6/libexec/src/net/http/transport.go:1887 +0x77
bufio.(*Reader).fill(0xc0001801e0)
/usr/local/Cellar/go/1.15.6/libexec/src/bufio/bufio.go:101 +0x105
bufio.(*Reader).Peek(0xc0001801e0, 0x1, 0x0, 0x0, 0x1, 0x0, 0xc0001d0060)
/usr/local/Cellar/go/1.15.6/libexec/src/bufio/bufio.go:139 +0x4f
net/http.(*persistConn).readLoop(0xc0000cea20)
/usr/local/Cellar/go/1.15.6/libexec/src/net/http/transport.go:2040 +0x1a8
created by net/http.(*Transport).dialConn
/usr/local/Cellar/go/1.15.6/libexec/src/net/http/transport.go:1708 +0xcb7
goroutine 41 [IO wait, 1 minutes]:
internal/poll.runtime_pollWait(0x1e91cb8, 0x72, 0x14e6ca0)
/usr/local/Cellar/go/1.15.6/libexec/src/runtime/netpoll.go:222 +0x55
internal/poll.(*pollDesc).wait(0xc00019e098, 0x72, 0x14e6c00, 0x16db878, 0x0)
/usr/local/Cellar/go/1.15.6/libexec/src/internal/poll/fd_poll_runtime.go:87 +0x45
internal/poll.(*pollDesc).waitRead(...)
/usr/local/Cellar/go/1.15.6/libexec/src/internal/poll/fd_poll_runtime.go:92
internal/poll.(*FD).Read(0xc00019e080, 0xc000326000, 0x1000, 0x1000, 0x0, 0x0, 0x0)
/usr/local/Cellar/go/1.15.6/libexec/src/internal/poll/fd_unix.go:159 +0x1a5
net.(*netFD).Read(0xc00019e080, 0xc000326000, 0x1000, 0x1000, 0x203000, 0x203000, 0x203000)
/usr/local/Cellar/go/1.15.6/libexec/src/net/fd_posix.go:55 +0x4f
net.(*conn).Read(0xc000186028, 0xc000326000, 0x1000, 0x1000, 0x0, 0x0, 0x0)
/usr/local/Cellar/go/1.15.6/libexec/src/net/net.go:182 +0x8e
net/http.(*connReader).Read(0xc00007c300, 0xc000326000, 0x1000, 0x1000, 0x100000006, 0x10, 0x1819408)
/usr/local/Cellar/go/1.15.6/libexec/src/net/http/server.go:798 +0x1ad
bufio.(*Reader).fill(0xc000290060)
/usr/local/Cellar/go/1.15.6/libexec/src/bufio/bufio.go:101 +0x105
bufio.(*Reader).ReadSlice(0xc000290060, 0xa, 0x1819408, 0xc000337988, 0x100f6d0, 0xc000110000, 0x100)
/usr/local/Cellar/go/1.15.6/libexec/src/bufio/bufio.go:360 +0x3d
bufio.(*Reader).ReadLine(0xc000290060, 0xc000110000, 0x1079694, 0xc0001a4000, 0x0, 0x1010038, 0x30)
/usr/local/Cellar/go/1.15.6/libexec/src/bufio/bufio.go:389 +0x34
net/textproto.(*Reader).readLineSlice(0xc000182300, 0xc000110000, 0x10d7c4d, 0xc00019e080, 0x1068000, 0xc000282900)
/usr/local/Cellar/go/1.15.6/libexec/src/net/textproto/reader.go:58 +0x6c
net/textproto.(*Reader).ReadLine(...)
/usr/local/Cellar/go/1.15.6/libexec/src/net/textproto/reader.go:39
net/http.readRequest(0xc000290060, 0x0, 0xc000110000, 0x0, 0x0)
/usr/local/Cellar/go/1.15.6/libexec/src/net/http/request.go:1012 +0xaa
net/http.(*conn).readRequest(0xc0000c6320, 0x14ed4a0, 0xc000322000, 0x0, 0x0, 0x0)
/usr/local/Cellar/go/1.15.6/libexec/src/net/http/server.go:984 +0x19a
net/http.(*conn).serve(0xc0000c6320, 0x14ed4a0, 0xc000322000)
/usr/local/Cellar/go/1.15.6/libexec/src/net/http/server.go:1851 +0x705
created by net/http.(*Server).Serve
/usr/local/Cellar/go/1.15.6/libexec/src/net/http/server.go:2969 +0x36c
این روش پروفایلگیری مشابه pprof.Lookup(debug=2) فراخوانی میشود، اما دادههای کاملاً متفاوتی تولید میکند:
- به جای لیست کردن هر گوروتین به صورت جداگانه، گوروتینهایی با استک و برچسبهای یکسان فقط یک بار همراه با تعداد آنها لیست میشوند.
- برچسبهای pprof در این حالت گنجانده میشوند، در حالی که
debug=2آنها را شامل نمیشود. - بیشتر ویژگیهای دیگر گوروتین که در
debug=2وجود دارند، در اینجا وجود ندارند. - فرمت خروجی همچنان به صورت متنی است، اما ظاهری بسیار متفاوت نسبت به
debug=2دارد.
در زیر یک نمونه کوتاه از خروجی برگردانده شده آورده شده است.
goroutine profile: total 9
2 @ 0x103b125 0x106cd1f 0x13ac44a 0x106fd81
# labels: {"test_label":"test_value"}
# 0x106cd1e time.Sleep+0xbe /usr/local/Cellar/go/1.15.6/libexec/src/runtime/time.go:188
# 0x13ac449 main.shortSleepLoop+0x29 /Users/felix.geisendoerfer/go/src/github.com/felixge/go-profiler-notes/examples/goroutine/main.go:165
1 @ 0x103b125 0x10083ef 0x100802b 0x13ac4ed 0x106fd81
# labels: {"test_label":"test_value"}
# 0x13ac4ec main.chanReceiveForever+0x4c /Users/felix.geisendoerfer/go/src/github.com/felixge/go-profiler-notes/examples/goroutine/main.go:177
1 @ 0x103b125 0x103425b 0x106a1d5 0x10d8185 0x10d91c5 0x10d91a3 0x11b8a8f 0x11cb72e 0x12df52d 0x11707c5 0x117151d 0x1171754 0x1263c2c 0x12d96ca 0x12d96f9 0x12e09ba 0x12e5085 0x106fd81
# 0x106a1d4 internal/poll.runtime_pollWait+0x54 /usr/local/Cellar/go/1.15.6/libexec/src/runtime/netpoll.go:222
# 0x10d8184 internal/poll.(*pollDesc).wait+0x44 /usr/local/Cellar/go/1.15.6/libexec/src/internal/poll/fd_poll_runtime.go:87
# 0x10d91c4 internal/poll.(*pollDesc).waitRead+0x1a4 /usr/local/Cellar/go/1.15.6/libexec/src/internal/poll/fd_poll_runtime.go:92
# 0x10d91a2 internal/poll.(*FD).Read+0x182 /usr/local/Cellar/go/1.15.6/libexec/src/internal/poll/fd_unix.go:159
# 0x11b8a8e net.(*netFD).Read+0x4e /usr/local/Cellar/go/1.15.6/libexec/src/net/fd_posix.go:55
# 0x11cb72d net.(*conn).Read+0x8d /usr/local/Cellar/go/1.15.6/libexec/src/net/net.go:182
# 0x12df52c net/http.(*connReader).Read+0x1ac /usr/local/Cellar/go/1.15.6/libexec/src/net/http/server.go:798
# 0x11707c4 bufio.(*Reader).fill+0x104 /usr/local/Cellar/go/1.15.6/libexec/src/bufio/bufio.go:101
# 0x117151c bufio.(*Reader).ReadSlice+0x3c /usr/local/Cellar/go/1.15.6/libexec/src/bufio/bufio.go:360
# 0x1171753 bufio.(*Reader).ReadLine+0x33 /usr/local/Cellar/go/1.15.6/libexec/src/bufio/bufio.go:389
# 0x1263c2b net/textproto.(*Reader).readLineSlice+0x6b /usr/local/Cellar/go/1.15.6/libexec/src/net/textproto/reader.go:58
# 0x12d96c9 net/textproto.(*Reader).ReadLine+0xa9 /usr/local/Cellar/go/1.15.6/libexec/src/net/textproto/reader.go:39
# 0x12d96f8 net/http.readRequest+0xd8 /usr/local/Cellar/go/1.15.6/libexec/src/net/http/request.go:1012
# 0x12e09b9 net/http.(*conn).readRequest+0x199 /usr/local/Cellar/go/1.15.6/libexec/src/net/http/server.go:984
# 0x12e5084 net/http.(*conn).serve+0x704 /usr/local/Cellar/go/1.15.6/libexec/src/net/http/server.go:1851
...
این روش پروفایلگیری دقیقاً مانند pprof.Lookup(debug=1) فراخوانی میشود و همان دادهها را تولید میکند. تنها تفاوت این است که فرمت دادهها به صورت پروتکل بافر pprof است.
در زیر یک نمونه کوتاه از خروجی برگشتی که توسط go tool pprof -raw گزارش شده است آورده شده است.
PeriodType: goroutine count
Period: 1
Time: 2021-01-14 16:46:23.697667 +0100 CET
Samples:
goroutine/count
2: 1 2 3
test_label:[test_value]
1: 1 4 5 6
test_label:[test_value]
1: 1 7 8 9 10 11 12 13 14 15 16 17 18 19 20
1: 1 7 8 9 10 11 12 21 14 22 23
test_label:[test_value]
1: 1 7 8 9 24 25 26 27 28 29 30
1: 1 31 32
test_label:[test_value]
1: 1 2 33
test_label:[test_value]
1: 34 35 36 37 38 39 40 41
test_label:[test_value]
Locations
1: 0x103b124 M=1 runtime.gopark /usr/local/Cellar/go/1.15.6/libexec/src/runtime/proc.go:306 s=0
2: 0x106cd1e M=1 time.Sleep /usr/local/Cellar/go/1.15.6/libexec/src/runtime/time.go:188 s=0
3: 0x13ac449 M=1 main.shortSleepLoop /Users/felix.geisendoerfer/go/src/github.com/felixge/go-profiler-notes/examples/goroutine/main.go:165 s=0
4: 0x10083ee M=1 runtime.chanrecv /usr/local/Cellar/go/1.15.6/libexec/src/runtime/chan.go:577 s=0
5: 0x100802a M=1 runtime.chanrecv1 /usr/local/Cellar/go/1.15.6/libexec/src/runtime/chan.go:439 s=0
6: 0x13ac4ec M=1 main.chanReceiveForever /Users/felix.geisendoerfer/go/src/github.com/felixge/go-profiler-notes/examples/goroutine/main.go:177 s=0
...
Mappings
1: 0x0/0x0/0x0 [FN]
این تابع در واقع یک slice از تمام گوروتینهای فعال و trace استک فعلی آنها را برمیگرداند. استک ترِیسها به صورت آدرسهای برنامه ارائه میشوند که میتوان آنها را با استفاده از تابع runtime.CallersFrames() به نامهای توابع ترجمه کرد.
این روش توسط fgprof برای پیادهسازی پروفایلگیری دیوار ساعت استفاده میشود.
ویژگیهای زیر در حال حاضر در دسترس نیستند، اما ممکن است برای پیشنهاد به پروژه Go در آینده جالب باشند:
- شامل کردن ویژگیهای گوروتینهایی که هنوز در دسترس نیستند، به خصوص برچسبها.
- فیلتر کردن بر اساس برچسبهای pprof، این کار میتواند stop-the-world را کاهش دهد، اما نیاز به نگهداری اضافی توسط runtime خواهد داشت.
- محدود کردن تعداد گوروتینهای بازگشتی به یک زیرمجموعه تصادفی، که میتواند stop-the-world را کاهش دهد و ممکن است پیادهسازی آن نسبت به فیلتر بر اساس برچسب آسانتر باشد.
در زیر یک مثال کوتاه از خروجی بازگشتی آورده شده است.
[
{
"Stack0": [
20629256,
20629212,
20627047,
20628306,
17018153,
17235329,
...
]
},
{
"Stack0": [
17019173,
17222943,
20628554,
17235329,
...
]
},
...
]
این پکیج پروفایلهای توصیفشده در بخش pprof.Lookup("goroutine") را از طریق endpointهای HTTP فراهم میکند. خروجی دقیقاً همان چیزی است که در روشهای دیگر دیده میشود.
4.25.2.5.5 تاریخچه #
پروفایلگیری گوروتین توسط Russ Cox پیادهسازی شد و برای اولین بار در نسخه weekly.2012-02-22 پیش از انتشار go1 ظاهر شد.
4.25.2.6 پروفایلر ThreadCreate #
🐞 پروفایل threadcreate برای نمایش استک ترِیسهایی طراحی شده که منجر به ایجاد نخهای (threads) جدید سیستمعامل شدهاند. با این حال، از سال ۲۰۱۳ خراب شده است، بنابراین بهتر است از آن دوری کنید.
4.25.3 آموزش کار با ابزار go pprof #
پروفایلرهای مختلف داخلی در Go برای کار با ابزار بصریسازی pprof طراحی شدهاند. pprof خود یک پروژه غیررسمی از گوگل است که برای تحلیل دادههای پروفایلگیری از برنامههای C++، Java و Go طراحی شده است. این پروژه یک فرمت پروتکل بافر را تعریف میکند که توسط تمام پروفایلرهای Go استفاده میشود و در این سند توضیح داده شده است.
پروژه Go خود یک نسخه از pprof را بههمراه دارد که میتوان آن را از طریق دستور go tool pprof فراخوانی کرد. این ابزار تا حد زیادی با ابزار اصلی مشابه است، بهجز چند تغییر جزئی. Go توصیه میکند که برای کار با پروفایلهای Go همیشه از go tool pprof بهجای ابزار اصلی استفاده شود.
4.25.3.1 ویژگیها #
ابزار pprof دارای یک رابط خط فرمان تعاملی است، اما همچنین یک رابط کاربری وب و گزینههای مختلف فرمت خروجی دیگر نیز دارد.
4.25.3.2 فرمت فایل #
فرمت pprof در تعریف پروتکل بافر profile.proto تعریف شده است که شامل نظرات مفیدی است. علاوه بر این، یک README رسمی برای آن وجود دارد. فایلهای pprof همیشه با فشردهسازی gzip در دیسک ذخیره میشوند.
یک تصویر به اندازه هزار کلمه میارزد، بنابراین در زیر یک تجسم خودکار تولید شده از این فرمت قرار داده شده است. لطفاً توجه داشته باشید که فیلدهایی مانند filename اشارهگرهایی به string_table هستند که در تجسم نشان داده نمیشوند و بهبودهای این حوزه خوشآمد است!
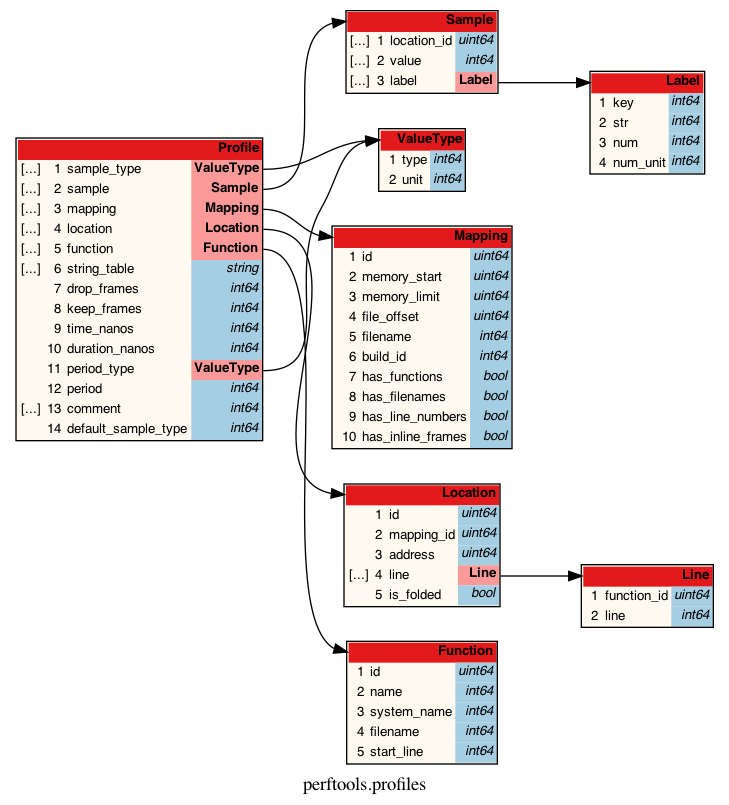
4.25.3.3 فرمت دادههای pprof #
فرمت دادههای pprof به نظر میرسد که برای کارایی، زبانهای مختلف و انواع پروفایلهای مختلف (CPU، Heap و غیره) طراحی شده است، اما به دلیل این موضوع، بسیار انتزاعی و پر از اشارهگری است. اگر میخواهید جزئیات کامل را مشاهده کنید، به لینکهای بالا مراجعه کنید. اگر به دنبال خلاصهای مختصر هستید، ادامه دهید:
یک فایل pprof شامل فهرستی از پشتههای تراشه است که به آنها نمونهها گفته میشود و یک یا چند مقدار عددی با آنها مرتبط است. برای یک پروفایل CPU، مقدار ممکن است مدت زمان CPU در نانوثانیه باشد که پشته تراشه در طول پروفایلسازی مشاهده شده است. برای یک پروفایل Heap، ممکن است تعداد بایتهای تخصیصیافته باشد. نوعهای مقداری خود در ابتدای فایل توصیف شده و برای پر کردن فهرست “نمونه” در رابط کاربری pprof استفاده میشوند. علاوه بر مقادیر، هر پشته تراشه میتواند شامل مجموعهای از برچسبها نیز باشد. برچسبها زوجهای کلید-مقدار هستند و حتی میتوانند شامل واحد نیز باشند. در Go، این برچسبها برای برچسبهای پروفایلر استفاده میشوند.
این پروفایل همچنین شامل زمان (در UTC) است که پروفایل ثبت شده و مدت زمان ضبط را نشان میدهد.
علاوه بر این، فرمت امکان استفاده از عبارات منظم drop/keep برای حذف یا شامل کردن برخی از پشتههای تراشه را فراهم میکند، اما آنها توسط Go استفاده نمیشوند. همچنین فضایی برای فهرستی از نظرات (توسط Go نیز استفاده نمیشود) و توصیف فاصله دورهای که در آن نمونهها گرفته شدهاند وجود دارد.
کد تولید خروجی pprof در Go در runtime/pprof/proto.go موجود است.
4.25.3.4 رمزگشایی (Decoding) #
در زیر تعدادی ابزار برای رمزگشایی فایلهای pprof به خروجی متنی قابل خواندن انسان آورده شده است. آنها بر اساس پیچیدگی فرمت خروجی خود مرتب شدهاند، به طوری که ابزارهایی که خروجی سادهتری ارائه میدهند ابتدا فهرست شدهاند:
4.25.3.5 استفاده از pprofutils
#
pprofutils ابزاری کوچک برای تبدیل بین فایلهای pprof و فرمت متنی جمع شده Brendan Gregg است (folded text). میتوانید از آن به صورت زیر استفاده کنید:
$ pprof2text < examples/cpu/pprof.samples.cpu.001.pb.gz
golang.org/x/sync/errgroup.(*Group).Go.func1;main.run.func2;main.computeSum 19
golang.org/x/sync/errgroup.(*Group).Go.func1;main.run.func2;main.computeSum;runtime.asyncPreempt 5
runtime.mcall;runtime.gopreempt_m;runtime.goschedImpl;runtime.schedule;runtime.findrunnable;runtime.stopm;runtime.notesleep;runtime.semasleep;runtime.pthread_cond_wait 1
runtime.mcall;runtime.park_m;runtime.schedule;runtime.findrunnable;runtime.checkTimers;runtime.nanotime;runtime.nanotime1 1
runtime.mcall;runtime.park_m;runtime.schedule;runtime.findrunnable;runtime.stopm;runtime.notesleep;runtime.semasleep;runtime.pthread_cond_wait 2
runtime.mcall;runtime.park_m;runtime.resetForSleep;runtime.resettimer;runtime.modtimer;runtime.wakeNetPoller;runtime.netpollBreak;runtime.write;runtime.write1 7
runtime.mstart;runtime.mstart1;runtime.sysmon;runtime.usleep 3
4.25.3.6 استفاده از go tool pprof
#
خود pprof دارای یک حالت خروجی به نام -raw است که محتوای یک فایل pprof را نمایش میدهد. با این حال، باید توجه داشت که این حالت آنچنان -raw نیست که میتوان به آن رسید، به protoc زیر نگاه کنید:
$ go tool pprof -raw examples/cpu/pprof.samples.cpu.001.pb.gz
PeriodType: cpu nanoseconds
Period: 10000000
Time: 2021-01-08 17:10:32.116825 +0100 CET
Duration: 3.13
Samples:
samples/count cpu/nanoseconds
19 190000000: 1 2 3
5 50000000: 4 5 2 3
1 10000000: 6 7 8 9 10 11 12 13 14
1 10000000: 15 16 17 11 18 14
2 20000000: 6 7 8 9 10 11 18 14
7 70000000: 19 20 21 22 23 24 14
3 30000000: 25 26 27 28
Locations
1: 0x1372f7f M=1 main.computeSum /Users/felix.geisendoerfer/go/src/github.com/felixge/go-profiler-notes/examples/cpu/main.go:39 s=0
2: 0x13730f2 M=1 main.run.func2 /Users/felix.geisendoerfer/go/src/github.com/felixge/go-profiler-notes/examples/cpu/main.go:31 s=0
3: 0x1372cf8 M=1 golang.org/x/sync/errgroup.(*Group).Go.func1 /Users/felix.geisendoerfer/go/pkg/mod/golang.org/x/sync@v0.0.0-20201207232520-09787c993a3a/errgroup/errgroup.go:57 s=0
...
Mappings
1: 0x0/0x0/0x0 [FN]
4.25.3.7 استفاده از protoc
#
برای کسانی که به دنبال دیدن دادهها نزدیک به ذخیرهسازی باینری خام هستند، ما به کامپایلر پروتکل بافر protoc نیاز داریم. در macOS میتوانید از brew install protobuf برای نصب آن استفاده کنید، برای سایر پلتفرمها به بخش نصب README مراجعه کنید.
حالا بیایید به همان پروفایل CPU از بالا نگاهی بیندازیم:
$ gzcat examples/cpu/pprof.samples.cpu.001.pb.gz | protoc --decode perftools.profiles.Profile ./profile.proto
sample_type {
type: 1
unit: 2
}
sample_type {
type: 3
unit: 4
}
sample {
location_id: 1
location_id: 2
location_id: 3
value: 19
value: 190000000
}
sample {
location_id: 4
location_id: 5
location_id: 2
location_id: 3
value: 5
value: 50000000
}
...
mapping {
id: 1
has_functions: true
}
location {
id: 1
mapping_id: 1
address: 20393855
line {
function_id: 1
line: 39
}
}
location {
id: 2
mapping_id: 1
address: 20394226
line {
function_id: 2
line: 31
}
}
...
function {
id: 1
name: 5
system_name: 5
filename: 6
}
function {
id: 2
name: 7
system_name: 7
filename: 6
}
...
string_table: ""
string_table: "samples"
string_table: "count"
string_table: "cpu"
string_table: "nanoseconds"
string_table: "main.computeSum"
string_table: "/Users/felix.geisendoerfer/go/src/github.com/felixge/go-profiler-notes/examples/cpu/main.go"
...
time_nanos: 1610122232116825000
duration_nanos: 3135113726
period_type {
type: 3
unit: 4
}
period:
10000000
این دستورات به ما این امکان را میدهند که ساختارهای ورودی و مقادیر خود را مشاهده کنیم، به ما کمک میکنند تا در نهایت فرمت را بهتر درک کنیم.
4.25.3.8 استفاده از net/http/pprof پروفایلینگ ریموت #
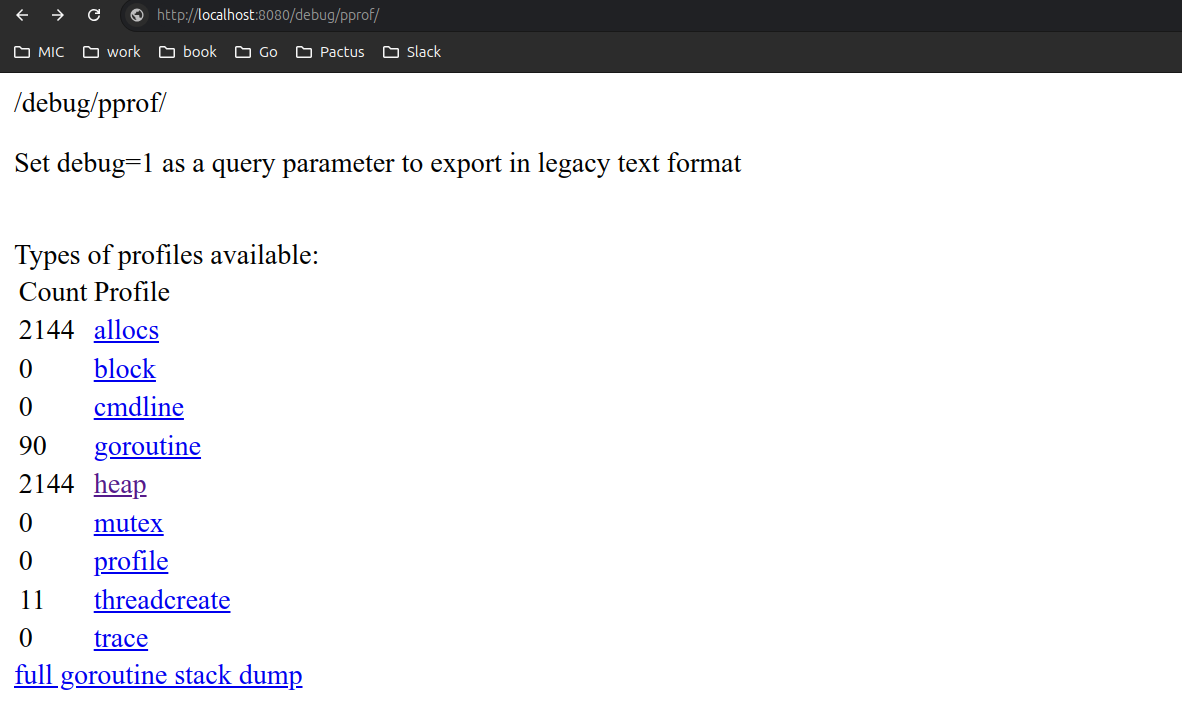
امکان دیباگ سرویس با استفاده از pprof برروی http.Server یا سایر وب سرورها. شما می توانید از پکیج net/http/pprof استفاده کنید اما دقت کنید ۲ مسئله وجود دارد باید در نظر بگیرید هنگام استفاده:
- زمانیکه این پکیج را در هر جایی از پروژه خود فراخوانی کنید تابع
init()داخل پکیج اجرا می شود و خودکار بهhttp.Handlerسرور mux اضافه می شود و نیازی به ریجستر کردن handler نیست اما اگر web framework های دیگر را استفاده میکنید باید بصورت دستی استفاده کنید. - امکان اینکه پکیج pprof قابلیت configuration شدن را داشته باشد ندارد و اطلاعات دیباگ خیلی حساس هستند اگر سرویس شما روی پروداکشن هست ممکن است اطلاعات حساسی بیرون درز دهد, به عنوان مثال
debug/pprof/cmdlineاطلاعات flag, switch هایی که سرویس شما اجرا شده است را نمایش می دهد و در صورتیکه فلگی داشته باشید شامل اطلاعات حساسی نظیر secret key, password و… باشد دیده می شود.
برای مورد دوم راه حلی داریم که می توانید جلو خودکار ریجستر شدن handler های pprof را بگیرید و موارد مورد نیاز را ریجستر کنید.
برای مورد دوم راه حلی داریم که می توانید جلو خودکار ریجستر شدن handler های pprof را بگیرید و موارد مورد نیاز را ریجستر کنید.
به نمونه کد زیر توجه کنید:
package main import ( "flag" "fmt" "github.com/PacViewer/synker/internal/logger" _ "go.uber.org/automaxprocs" "net/http" "net/http/pprof") var ( pprofAddr *string ) func init() { pprofAddr = flag.String("pprof-addr", "", "start pprof on server") flag.Parse() // init disables default pprof handlers registered by importing net/http/pprof. // Your pprof is showing (https://mmcloughlin.com/posts/your-pprof-is-showing) http.DefaultServeMux = http.NewServeMux() } func main() { log := logger.DefaultLogger if *pprofAddr != "" { mux := http.NewServeMux() mux.HandleFunc("/debug/pprof/", pprof.Index) mux.HandleFunc("/debug/pprof/profile", pprof.Profile) mux.HandleFunc("/debug/pprof/symbol", pprof.Symbol) mux.HandleFunc("/debug/pprof/trace", pprof.Trace) sv := &http.Server{ Addr: *pprofAddr, Handler: mux, } log.Info("pprof listened", "addr", fmt.Sprintf("http://%s/debug/pprof", *pprofAddr)) go func() { if err := sv.ListenAndServe(); err != nil { log.Fatal("failed to listen pprof server", "err", err) } }() } }
پس از اینکه net/http/pprof را ریجستر کردید برروی سرور روی روت /debug/pprof در دسترس است.
4.25.3.9 دستورات pprof #
در زیر ما یکسری دستوارت کاربردی pprof را معرفی میکنیم که میتوانید بصورت visualization اطلاعات پروفایل را در لوکال یا ریموت ببینید.
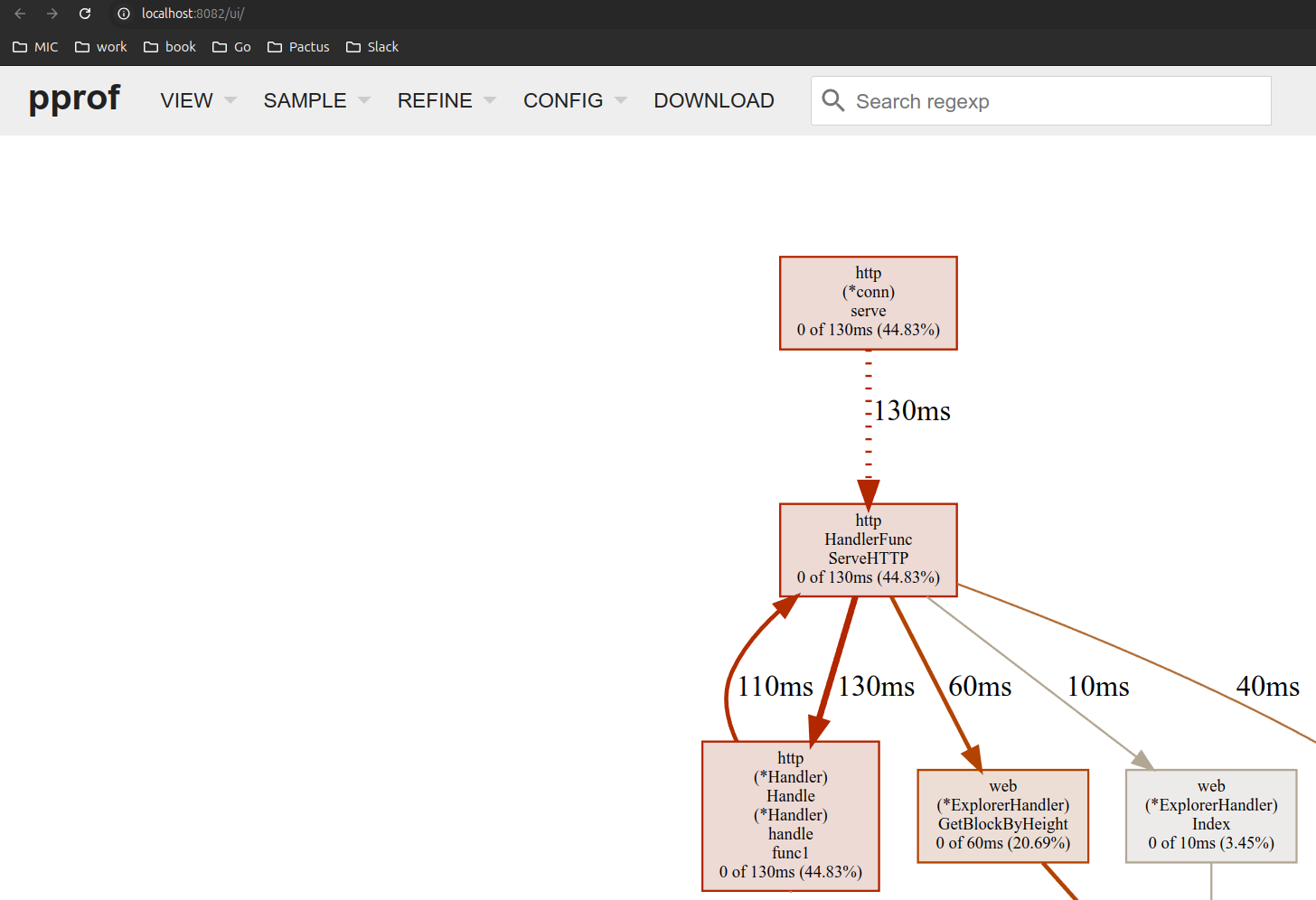
4.25.3.9.1 دیدن CPU Profile آنلاین روی لوکال #
برای دیدن اطلاعات CPU Profile بصورت آنلاین روی لوکال دستور زیر را بزنید:
go tool pprof -http=:8081 http://localhost:8080/debug/pprof/profile
4.25.3.9.2 دیدن Memory Profile آنلاین روی لوکال #
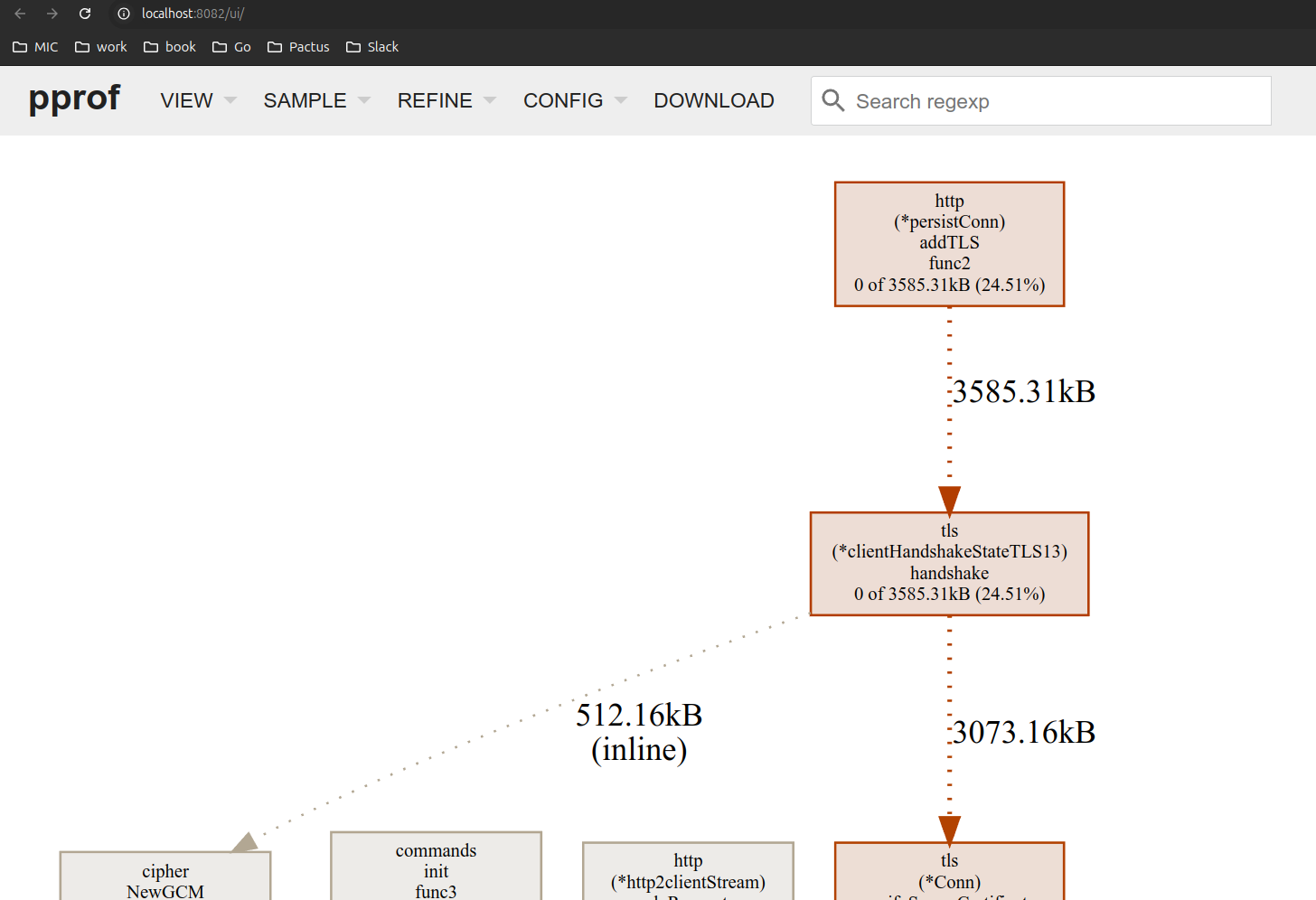
برای دیدن اطلاعات Memory Profile بصورت آنلاین روی لوکال دستور زیر را بزنید:
- دیدن allocation ها
go tool pprof -http=:8081 http://localhost:8080/debug/pprof/allocs
- دیدن heap ها
go tool pprof -http=:8081 http://localhost:8080/debug/pprof/heap
برای دیدن در قالب flame graph می توانید به آدرس زیر برروید:
http://localhost:8082/ui/flamegraph
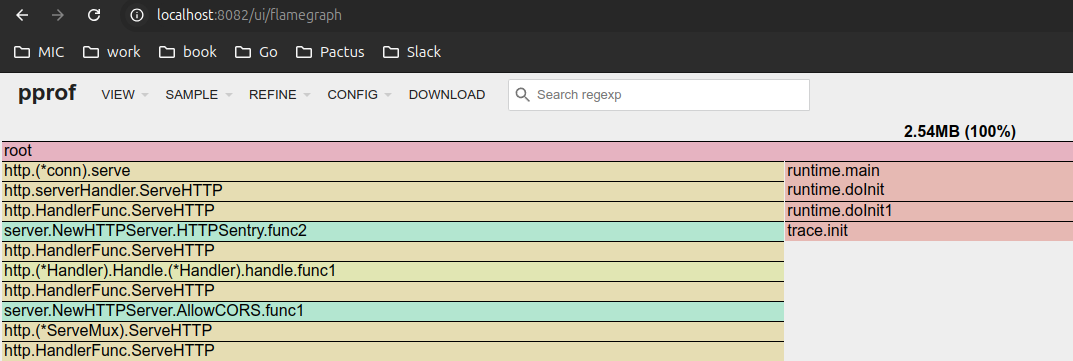
4.25.3.9.3 گرفتن خروجی pdf, png, svg #
برای اینکه بتوانید از اطلاعات profiling خروجی فایل بگیرید دستور زیر را بزنید.
go tool pprof -pdf heap_profile.pprof
- SVG
go tool pprof -svg heap_profile.pprof
- PNG
go tool pprof -png heap_profile.pprof
4.25.3.9 نتیجهگیری #
مدیریت کارآمد حافظه در Go، به همراه ابزارهای پروفایلسازیاش، به توسعهدهندگان پلتفرمی قوی برای ساخت برنامههای کارآمد ارائه میدهد. با درک رفتار حافظه در Go و پروفایلسازی منظم برنامه خود، میتوانید اطمینان حاصل کنید که این برنامه حتی در بارهای سنگین نیز کارآمد و پاسخگو باقی میماند.